一文看懂RAG的前世今生
1. 大语言模型(LLM)的局限性
- LLM 容易出现“幻觉”现象,即生成不准确或虚构的内容。
- LLM 的上下文窗口有限,无法处理过长的文本。
- LLM 存在隐私泄露的风险,也就是数据安全问题。
为了弥补这些不足 RAG(检索增强生成)技术应运而生,也就是最早的Naive(朴素的) RAG或者说Vanilla(普通的) RAG
使用如BM25(TF-IDF)或者Dense(Embedding) Retrieval的方式。
2. RAG技术在适应复杂应用场景和不断发展的技术需求中经历了从Naive RAG ,到流程优化的 Advanced RAG,再到更具灵活性的 Modular RAG 的演变。
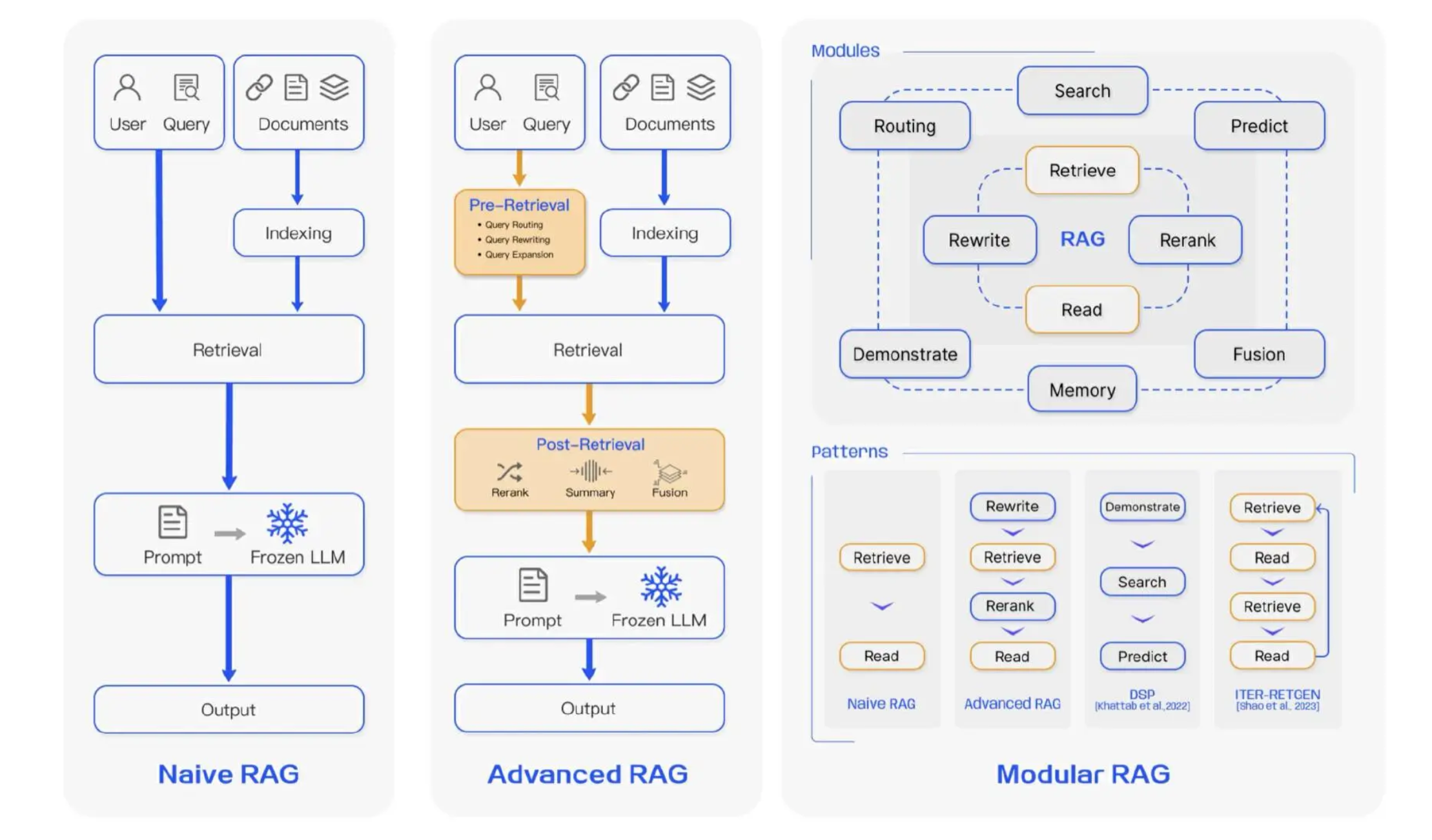
Advanced RAG
检索前优化
检索前优化通过索引、分块、查询优化以及内容向量化等技术手段,提高检索内容的精确性和生成内容的相关性。
- 滑动窗口方法:经典的分块技术,通过在相邻的文本块之间创建重叠区域,确保关键信息不会因简单的分段而丢失。这种方法在索引过程中通过在块之间保留重复部分,保证了检索时上下文信息的连贯性,进而提高了检索的精度。
- 元数据添加:为每个分块添加元数据(如创建日期、章节名称、文档类型等),能够使系统在检索时快速过滤掉无关内容。例如,用户在查询时可以通过元数据筛选特定时间段的文档,减少不相关信息的干扰。
- 分层索引:在索引过程中,可以采用句子级、段落级甚至文档级的多层次嵌入方法。这样,系统可以根据查询的具体要求,灵活地在不同层次进行检索。比如,当用户输入较为复杂的长句查询时,段落级别的嵌入能够提供更加全面的语义匹配;而对于简短查询,句子级的嵌入能够提供更精确的结果。
- 句子窗口检索:这种方法通过将文档中的每个句子独立嵌入,从而提高检索的精确度。在检索过程中,系统找到与查询最相关的句子后,会扩展句子前后的上下文窗口,保证生成模型能够获取足够的背景信息进行推理。这种方式既能够精准定位关键信息,又能确保生成的上下文连贯性。
- 查询重写:针对用户输入的原始查询进行重新表述,使其更加清晰易懂,并且与检索任务匹配。例如,针对用户模糊或含糊的提问,系统可以通过重写,使查询更加具体化,从而检索到更加精准的内容。
- 查询扩展:查询扩展通过增加同义词、相关词汇或概念扩展用户的原始查询,增加了检索结果的广度。这样,当用户输入简短或不完整的查询时,系统能够通过扩展词汇找到更多潜在相关的内容,从而提升检索效果。
- 长短不一的内容向量化:RAG 系统中,文档或查询的长度对向量化过程有着显著的影响。对于短句子或短语,其生成的向量更加聚焦于具体细节,能够实现更精确的句子级别匹配。段落或文档级别的向量化涵盖了更广泛的上下文信息,能够捕捉到内容的整体语义。
检索优化
检索优化是 RAG 系统中直接影响检索效果和质量的核心环节。通过增强向量搜索、动态嵌入模型、混合检索等技术手段,系统能够高效、精准地找到与用户查询最相关的内容。
- 动态嵌入:RAG 系统通过动态嵌入模型根据上下文变化实时调整单词的嵌入表示,能够捕捉单词在不同上下文中的不同含义。例如,“bank”在“river bank”(河岸)和“financial bank”(银行)中的语义完全不同,动态嵌入可以根据具体语境生成合适的向量,从而提高检索的精准性。
- 领域特定嵌入微调:在实际应用中,不同领域的数据语境差异较大,通用的嵌入模型往往无法覆盖某些领域的专业术语或特定语义。通过对嵌入模型进行微调,可以增强其在特定领域中的表现。例如,针对医学、法律等专业领域,可以对嵌入模型进行定制化训练 / 微调,使其更好地理解这些领域中的特有词汇和语境。
- 假设文档嵌入:假设文档嵌入(Hypothetical Document Embeddings,HyDE)是一种创新的检索技术。HyDE 方法通过生成假设文档并将其向量化,以提升查询与检索结果之间的语义匹配度。当用户输入一个查询时,LLM 首先基于查询生成一个假设性答案,这个答案不一定是真实存在的文档内容,但它反映了查询的核心语义。然后,系统将该假设性答案向量化,与数据库中的向量进行匹配,寻找最接近的文档。例如,用户询问“拔除智齿需要多长时间?”,系统会生成一个假设性回答“拔智齿通常需要 30 分钟到两小时”,然后根据该假设文档进行检索,系统可能最终找到类似的真实文档,如“拔智齿的过程通常持续几分钟到 20 分钟以上”。通过假设文档,系统可以捕捉到更准确的相关文档。
- 混合检索:混合检索是结合向量搜索与关键词搜索等多种检索方法的混合方法,能够同时利用语义匹配与关键词匹配的优势。
- 小到大检索:这种方法首先通过较小的内容块(如单个句子或短段落)进行嵌入和检索,确保模型能找到与查询最匹配的小范围上下文。检索到相关内容后,再在生成阶段使用对应的较大文本块(如完整段落或全文)为模型提供更广泛的上下文支持。小块检索有助于提高精度,而大块生成则提供丰富的背景信息,使得生成的内容更加全面。
- 递归块合并:通过逐级扩展检索内容,确保生成阶段能够捕捉到更全面的上下文信息。该技术在细粒度的子块检索后,自动将相关的父块合并,以便提供完整的上下文供生成模型参考。
检索后优化
检索后优化目的是对已经检索到的内容进行进一步的处理和筛选,常用的技术包括重排序、提示压缩等,以确保最终生成的答案具有高度的相关性和准确性。
- 重排序:在 RAG 系统中,虽然初始检索可以找到多个与查询相关的内容块,但这些内容的相关性可能存在差异,因此需要进一步排序以优化生成结果。重排序通过重排序模型根据上下文的重要性、相关性评分等因素对已检索内容重新打分,以确保最相关的信息被优先处理。
- 提示压缩:通过删除冗余信息、合并相关内容、突出关键信息等方式来压缩提示,为生成模型提供更简洁、更相关的输入。
- 上下文重构:通过对检索到的内容进行再加工或重组,以便更好地符合查询的需求。常见的做法是将多个检索到的上下文片段整合成一个更具连贯性的文本块,减少重复或冲突的内容,从而为生成模型提供一个统一、清晰的输入。
- 内容过滤:根据预先设定的规则进行,包括过滤掉与查询无直接关联的内容、语义相似度较低的片段、冗长且无关的背景信息等,避免对生成结果产生负面影响。
- 多跳推理:系统通过多个推理步骤,逐步整合信息,以回答复杂查询。通常用于需要跨多个上下文或多步推理的问题。例如,用户询问“某个技术的演化历程”,系统可能先检索到该技术的某个时间点的关键事件,然后再通过进一步检索,找到关于这些关键事件的详细说明,最终给出完整的回答。
- 知识注入:在检索后通过外部知识库或预定义的领域知识,增强生成的上下文内容。这种方式适用于对准确性要求较高的场景,尤其是在特定领域或技术场景下,系统需要补充额外的专业知识。
Modular RAG
编排模块(Orchestration) 是 Modular RAG 区别于 Advanced RAG 的核心,它通过灵活的路由、调度、知识引导与推理路径来动态决定处理流程,从而提升了整个系统在复杂查询场景下的适应性和处理能力。
-
Routing(路由)
路由是编排流程中的关键步骤。它的主要功能是在收到用户查询后,根据查询的特点和上下文,选择最合适的流程。具体来说,Routing 模块依赖于以下两部分:
a. Query Analysis(查询分析):首先,对用户的查询进行语义分析,判断其类型和难度。例如,一个直接问答式的查询可能不需要复杂的检索过程,而一个涉及多步推理的复杂问题则可能需要走更长的检索路径。
b. Pipeline Selection(管道选择):根据查询分析的结果,Routing 模块会动态选择合适的流程(Pipeline)。比如针对简单的查询,可以仅用大模型的知识来回答,效率高。而针对需要领域知识及复杂推理的查询,系统会使用更多的检索步骤,结合外部文档及知识进行深度检索生成。
-
Scheduling(调度)
调度的作用是管理查询的执行顺序,并动态调整检索和生成步骤。
a. Query Scheduling(查询调度):当系统接收到查询时,调度模块会判断是否需要进行检索。调度模块根据查询的重要性、上下文信息、已有生成结果的质量等多维度因素进行评估。
b. Judgment of Retrieval Needs(检索需求判断):调度还通过特定的判断节点来确定是否需要额外检索。在某些情况下,系统可能会多次判断是否有必要执行新一轮的检索。
-
Knowledge Guide(知识引导)
知识引导是结合知识图谱和推理路径来增强查询处理过程。
a. Knowledge Graph(知识图谱):在处理复杂查询时,系统可以调用知识图谱来辅助检索。这不仅提升了检索结果的准确性,还可以通过知识图谱中的上下文关系来推导出更为精确的答案。例如,若查询涉及多个实体的关系或多个时间点,知识图谱能够提供更深层次的推理支持。
b. Reasoning Path(推理路径):通过推理路径,系统可以设计出一条符合查询需求的推理链条,系统可以根据这一链条进行逐步地推理和检索。这在处理具有强逻辑性的问题时非常有效,例如跨多个文档的关系推理或时间序列推导。
Modular RAG 进一步增强了 RAG 系统的灵活性和适应性,允许通过不同模块的自由组合来应对多样化的应用场景,实现了更加智能的流程控制和动态决策。
3. GraphRAG解决向量检索面临的两个主要挑战(无法捕捉人类长期记忆的两个关键特征)
• 意义构建(sense-making):即归纳总结,指理解大规模或复杂事件的能力,标准的RAG方法在处理需要理解大规模或复杂事件、经历或数据的能力(即情境理解)方面存在不足。这种能力对于理解和推理长篇故事或复杂文本至关重要。
• 关联性(associativity):关联性则是指在不同知识片段之间建立多跳连接的能力,难以在多跳问答任务中表现出色,因为它们依赖于独立的向量检索,无法有效地在多个信息片段之间建立多跳连接。这对于需要从不同来源或段落中提取信息来回答问题是关键的限制。
为了解决这些挑战,微软提出了 GraphRAG,通过利用大模型生成的知识图谱来改进 RAG 的检索部分。GraphRAG 的核心创新在于利用结构化的实体和关系信息,使检索过程更加精准和全面,特别在处理多跳问题和复杂文档分析时表现突出。
GraphRAG的原理:
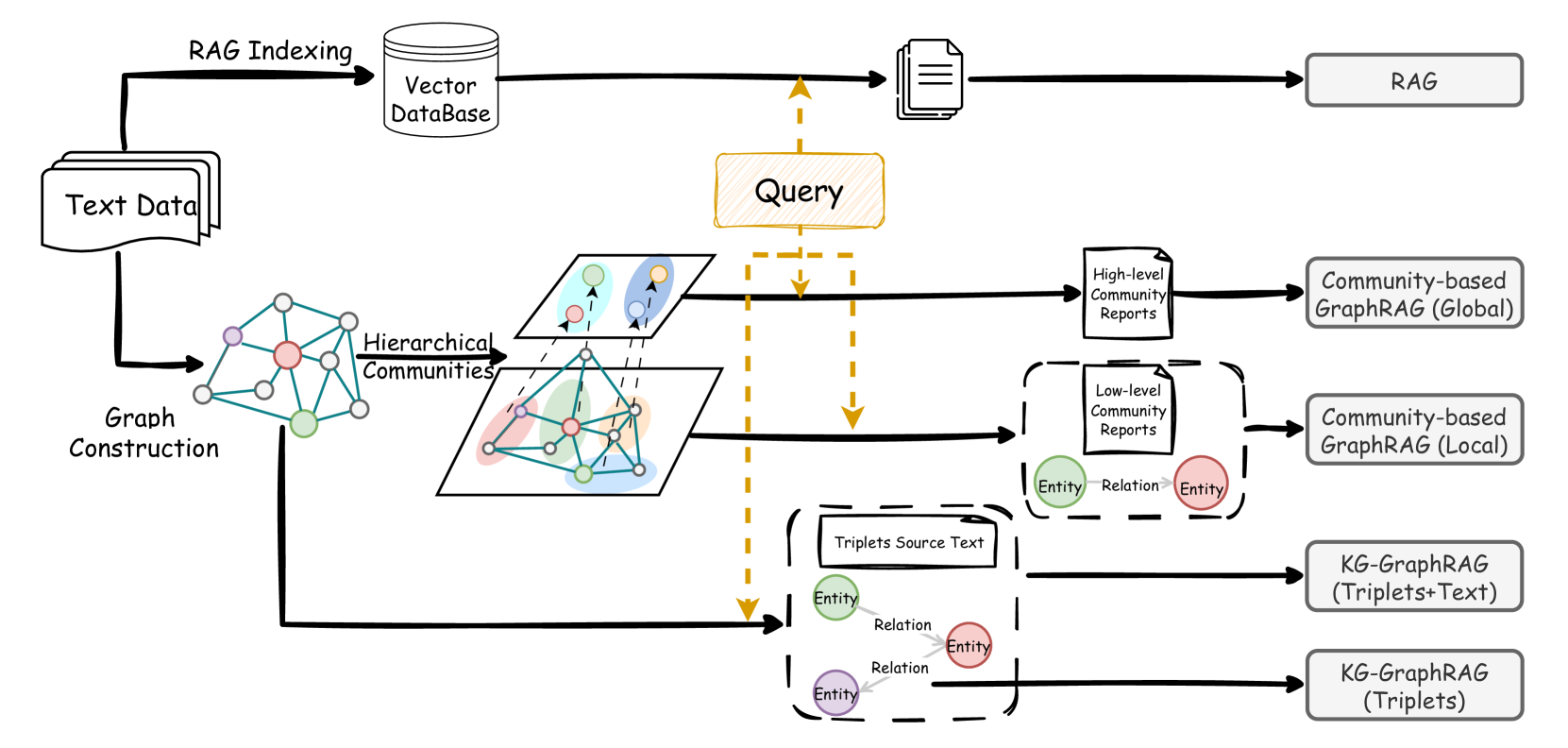
传统RAG和GraphRAG对比:
9种GraphRAG对比:(并附上各种方法已有的开源实现)
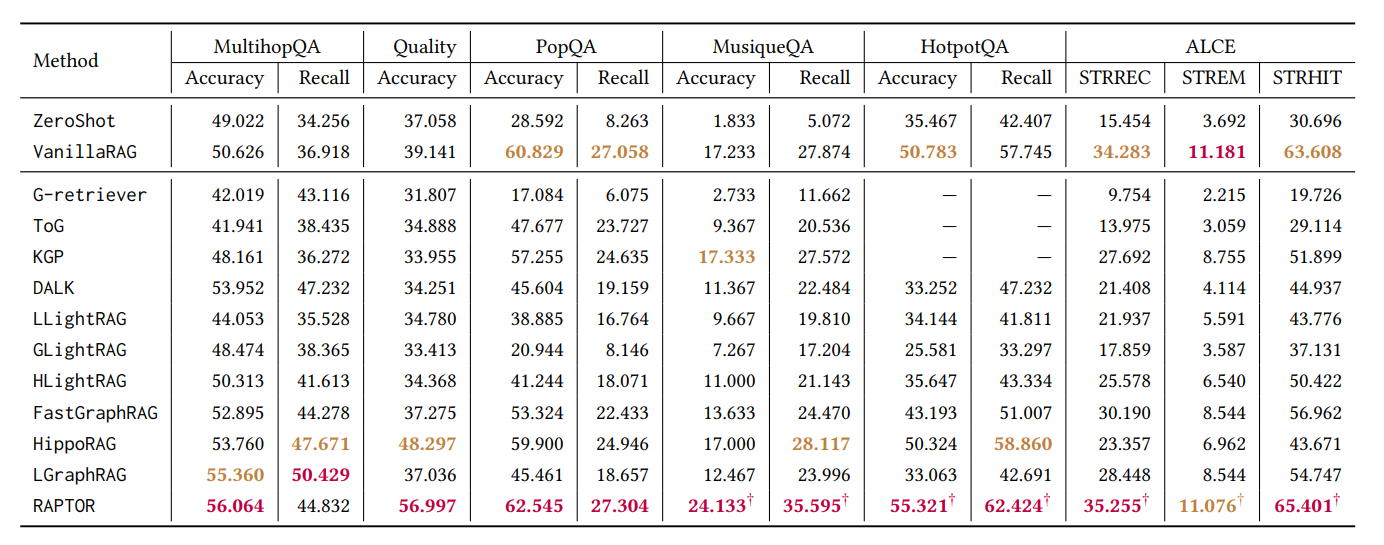
以下是表格中所有方法的简要解释,按它们在表格中出现的顺序排列:
1. ZeroShot(基于HuggingFace Transformers实现)
- 定义:零样本方法(Zero-Shot)指模型在未经特定数据集训练的情况下直接进行预测或推理。
- 特点:依赖预训练模型的泛化能力,无需微调或示例(prompt engineering)。
- 适用场景:快速基线测试或资源受限的任务。
2. VanillaRAG(基于langchain库实现 https://github.com/langchain-ai/langchain)
- 定义:标准的检索增强生成(Retrieval-Augmented Generation)方法,结合检索模块(如BM25/Dense Retrieval)和生成模型(如LLM)。
- 特点:通过检索相关文档辅助生成答案,但未针对复杂任务优化。
- 适用场景:通用问答任务,性能中等。
3. G-retriever(https://github.com/XiaoxinHe/G-Retriever)
- 定义:基于图的检索方法(Graph-based Retriever),可能利用知识图谱或文档间关系改进检索。
- 特点:强调结构化检索,但在表格中表现较差(部分数据集结果缺失)。
- 适用场景:需结构化信息的任务,但可能计算成本高。
4. TGG
- 定义:Transition-based Graph Generation,一种基于状态转移的图生成方法。
- 特点:通过动态构建图结构优化检索或生成,性能中等。
- 适用场景:多跳问答或复杂推理任务。
5. KGP
- 定义:Knowledge-Guided Prompting,利用外部知识库引导生成。
- 特点:结合显式知识增强模型,在PopQA等数据集表现较好。
- 适用场景:需要外部知识支持的问答。
6. DALK
- 定义:Dynamic Adaptive Latent Knowledge,动态调整潜在知识表示的方法。
- 特点:在MultihopQA和HotpotQA中表现突出(紫色标记),但其他任务不稳定。
- 适用场景:动态适应复杂查询的任务。
7. LLightRAG / GLightRAG / HLightRAG(https://github.com/HKUDS/LightRAG)
- 定义:轻量级RAG变体,可能通过不同优化策略(如Local、Global或Hybrid检索)降低计算成本。
- 特点:
- LLightRAG:局部优化,性能中等。
- GLightRAG:全局优化,但在PopQA表现较差。
- HLightRAG:混合策略,综合性能较好。
- 适用场景:资源受限环境下的平衡方案。
8. FastGraphRAG(https://github.com/circlemind-ai/fast-graphrag)
- 定义:快速图结构RAG,可能通过简化图构建或检索流程提升效率。
- 特点:在多个数据集(如MultihopQA、ALCE)表现接近最佳(橙色标记)。
- 适用场景:需速度和性能兼顾的任务。
9. HippoRAG(https://github.com/OSU-NLP-Group/HippoRAG)
- 定义:Hierarchical Iterative Path-based RAG,通过分层路径优化多跳推理,是一种受人类长期记忆启发的新型RAG框架,使 LLM 能够持续整合外部文档中的知识。RAG +知识图谱+个性化网页排名。
- 特点:在Quality和MusiqueQA中表现最佳(紫色标记),但其他任务一般。
- 适用场景:需要分层推理的复杂问答。
10. LGraphRAG(https://github.com/microsoft/graphrag)
- 定义:Latent Graph RAG,隐式学习文档间关系构建图结构。
- 特点:在MultihopQA的Accuracy和Recall上最优(紫色标记)。
- 适用场景:隐式关系建模任务。
11. RAPTOR(https://github.com/parthsarthi03/raptor)
- 定义:Recursive Abstractive Processing for Tree-Organized Retrieval,递归处理树状检索结构的方法。
- 特点:
- 在最大数据集上改用K-means(因Gaussian Mixture计算超时)。
- 在MusiqueQA、ALCE等多项任务中全面领先(紫色/橙色标记)。
- 适用场景:大规模、复杂数据集上的高性能需求。
小结
- 最佳方法:RAPTOR综合表现最强,DALK和LGraphRAG在特定任务领先。
- 轻量级选择:FastGraphRAG或HLightRAG适合效率优先场景。
- 知识依赖:KGP和HippoRAG在知识密集型任务中表现优异。
4. Agentic RAG(详细内容可查看论文地址)(附上开源实现)
Agentic RAG(基于智能代理的检索增强生成)是传统 RAG(Retrieval-Augmented Generation) 技术的增强版本,它通过引入 AI Agent(人工智能代理) 的动态规划、自主决策和多步推理能力,使RAG系统能够更智能地处理复杂查询任务。
Agentic RAG 的核心特点
- 动态任务编排
- 根据用户查询的意图,自动选择不同的检索策略(如向量搜索、知识图谱查询、摘要索引等)714。
- 支持多步骤推理(Multi-hop Reasoning),例如分解复杂问题为多个子查询并逐步解答58。
- 查询优化与反馈机制
- 如果初始检索结果不理想,Agentic RAG 可以自动改写查询或调整检索策略214。
- 具备 反思(Self-Reflection) 能力,评估检索结果的质量并决定是否需要重新检索14。
- 多数据源与工具集成
- 可结合外部工具(如Web搜索、数据库查询、API调用)来增强回答的准确性8。
- 支持跨文档、跨模态(文本、图像、结构化数据)的信息整合5。
- 模块化架构
- 可采用单Agent(统一规划)或多Agent(分层协作)架构,例如:
- Tool Agent:负责特定知识库的检索(如向量索引、摘要引擎)。
- Top Agent:协调多个Tool Agent,规划全局任务7。
- 可采用单Agent(统一规划)或多Agent(分层协作)架构,例如:
AI代理RAG系统的基本实现
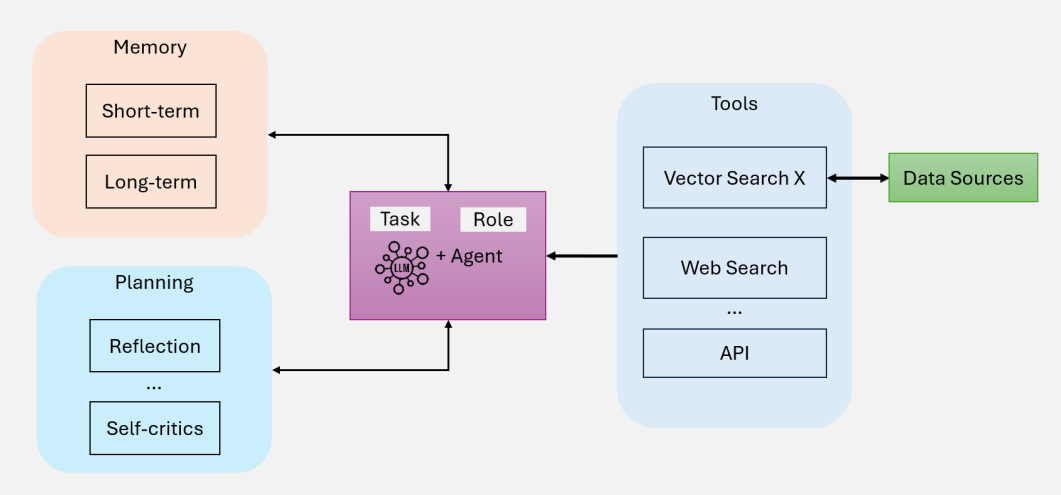
多代理RAG系统
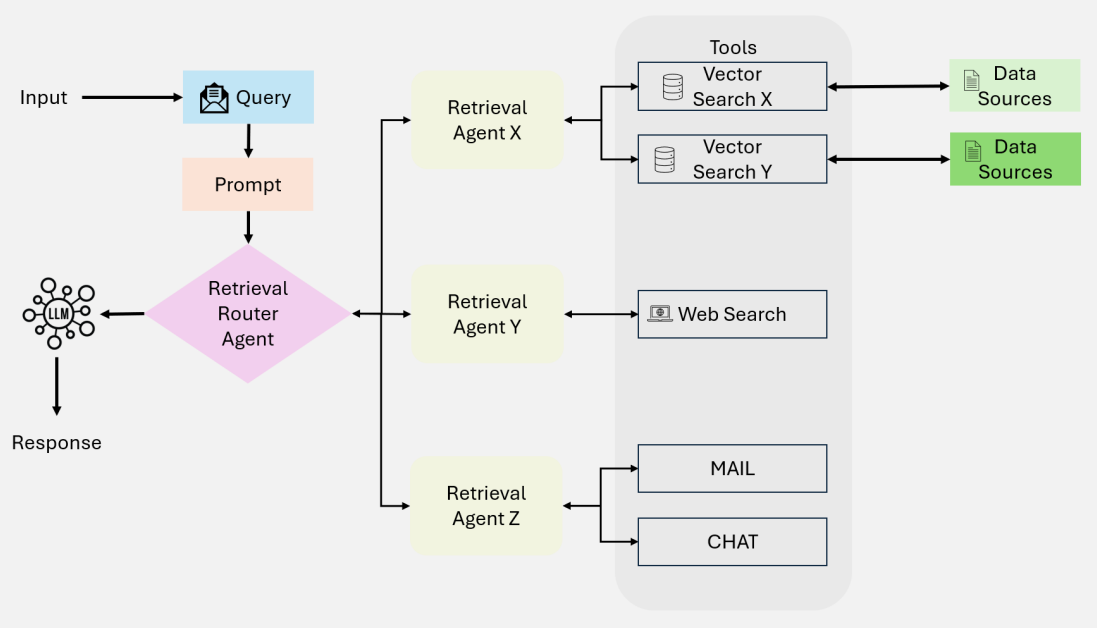
5. 最终总结
RAG范式的对比分析
| 范式 | 核心特点 | 优势 |
|---|---|---|
| 基础RAG | • 基于关键词的检索(如TF-IDF、BM25) | • 简单易实现 • 适合事实型查询 |
| 高级RAG | • 稠密检索模型(如DPR) • 神经排序与重排序 • 多跳检索 |
• 检索精度高 • 上下文相关性更强 |
| 模块化RAG | • 混合检索(稀疏+稠密) • 工具与API集成 • 可组合的领域专用流程 |
• 灵活性和可定制性高 • 适合多样化应用场景 • 可扩展性强 |
| 图RAG | • 基于图结构的集成 • 多跳推理 • 通过节点实现上下文增强 |
• 支持关系推理 • 减少幻觉生成 • 适合结构化数据任务 |
| 智能体RAG | • 自主智能体 • 动态决策 • 迭代优化与工作流调整 |
• 实时适应变化 • 支持多领域任务扩展 • 准确性高 |
关键术语说明
- 多跳检索(Multi-hop Retrieval):通过多次检索逐步获取答案,适合复杂问题。
- 稠密检索(Dense Retrieval):使用神经网络(如DPR)将查询和文档映射为向量进行相似度匹配。
- 图结构(Graph-based):用节点和边表示数据关系,增强推理能力(如知识图谱)。
- 自主智能体(Autonomous Agents):能独立规划、决策和优化的AI代理。