RAG生成(一):大模型的选择
RAG的生成流程
生成流程中,首先需要组合指令,指令将携带查询问题及检索到的相关信息输入到大模型中,由大模型理解并生成最终的回复,从而完成整个应用过程。
在这个过程中,有两个环节直接影响RAG系统的生成效果:
1. 大模型的选择:大模型相当于RAG系统的大脑,决定着RAG系统的响应质量。
2. 提示词工程:通过有效的指令的设计和组合,可以帮助大模型更好的理解内容和生成更加精确和相关的回答。
大模型的发展

SuperCLUE 组织发布的中文大模型全景图,展示了 2025 年值得关注的中文大模型,从文本、多模态、行业三个层面进行了详细分类,各领域的大模型应用层出不穷。RAG 中目前更关注通用大模型,比如闭源的文心一言、通义千问、腾讯混元、字节豆包、Kimi Chat 等都是可选择的大模型组件,如果需要私有化部署,Deepseek、Qwen 系列、GLM 系列、Baichuan 系列都在可考虑范围。

更多包含机构和学术背景且具有明确来源的大模型信息,可以访问实时更新的 中国大模型列表 全面记录中国大模型的发展动态。
大模型原理
一切始于 Google 在 2017 年发表的论文 《Attention Is All You Need》,引入了 Transformer 模型,它是深度学习领域的一个突破性架构,大型语言模型的成功得益于对 Transformer 模型的应用。
与传统的循环神经网络(RNN)相比,Transformer 模型不依赖于序列顺序,而是通过自注意力(Self-Attention)机制来捕捉序列中各元素之间的关系。Transformer 由多个堆叠的编码层(Encoder)和解码层(Decoder)组成,每一层包括自注意力层、前馈层和归一化层。这些层协同工作,逐步捕捉输入数据信息特征,从而预测输出,实现强大的语言理解和生成能力。
Transformer 模型的核心创新在于位置编码和自注意力机制。位置编码帮助模型理解输入数据的顺序信息,而自注意力机制则允许模型根据输入的全局上下文,为每个词元分配不同的注意力权重,从而更准确地理解词与词之间的关联性。这种机制使得 Transformer 特别适用于语言模型,因为语言模型需要精确捕捉上下文中的细微差别,生成符合语义逻辑的文本。
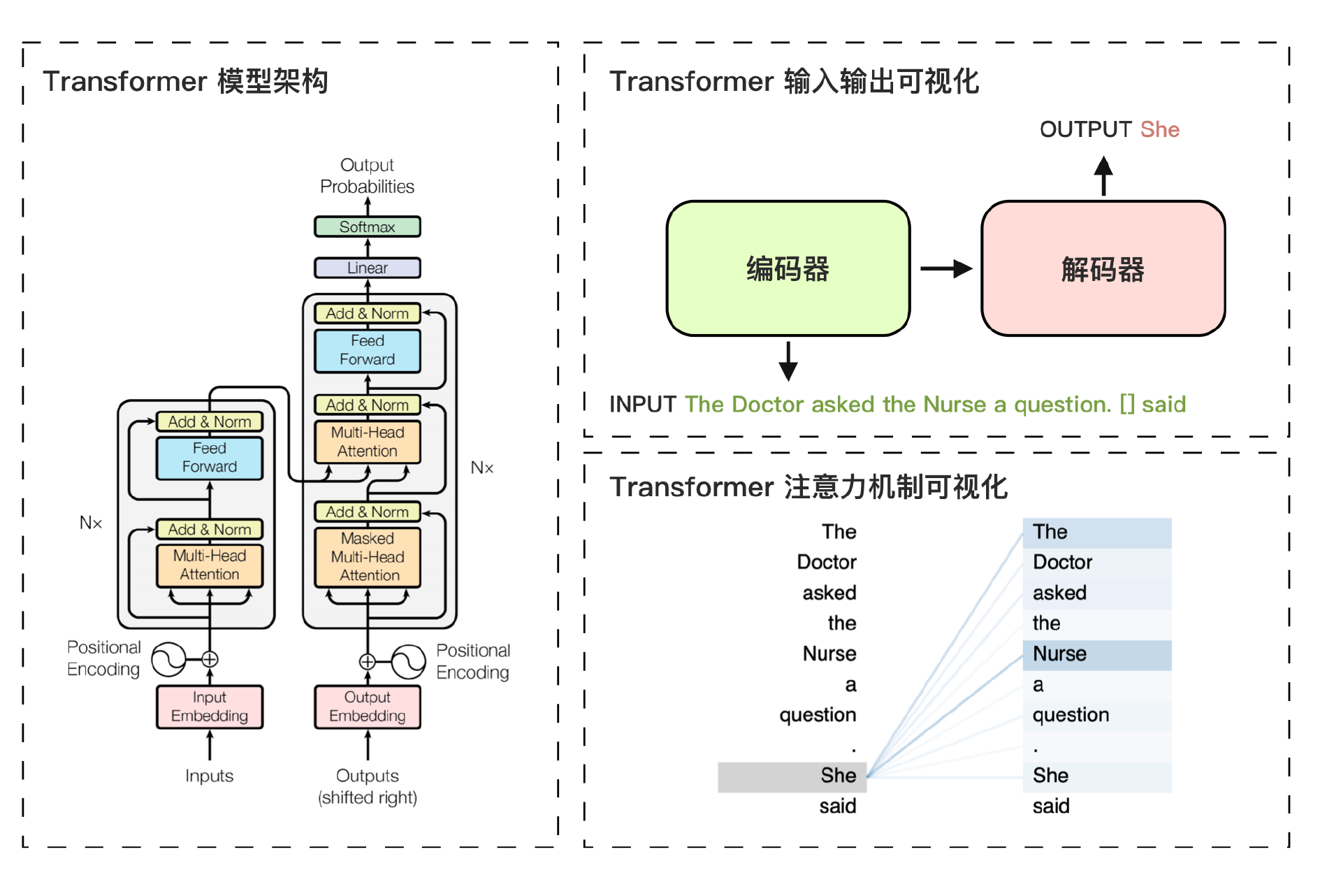
上图展示了 Transformer 模型的架构及其核心机制的可视化示例。左图中,Transformer 模型由编码器和解码器两部分组成。编码器负责理解输入信息的顺序和语义,解码器则输出概率最高的词元。
右上图中的示例显示了输入句子中的填空任务,解码器依据输入句子的特征和已生成的部分句子,生成了“She”作为模型的预测结果。生成“She”的核心原因在于右下图所示的注意力机制,其中需要填空的部分对输入句子中的词元“The Doctor”和“Nurse”分配了较高的注意力权重,从而提高了“She”作为输出词元的生成概率。
大语言模型的突破始于 2022 年年底 OpenAI 发布的 ChatGPT。其核心优势体现在庞大的参数规模(数百亿甚至数千亿)、基于 PB 级别数据的训练所带来的卓越语言理解与生成能力,以及其显著的涌现能力。 大语言模型不仅在传统的自然语言处理任务中展现了卓越表现,还具备了解决复杂问题和进行逻辑推理等高级认知能力。
RAG中大模型的选择
在如今大模型层出不穷的情况下,如何在 RAG 应用场景中选择合适的模型呢?我们面对的是开源与闭源的选择、大参数与小参数的对比,成本的考虑以及云端与私有化部署的抉择。针对这些问题,我们需要结合测评和具体的应用场景进行综合考量。
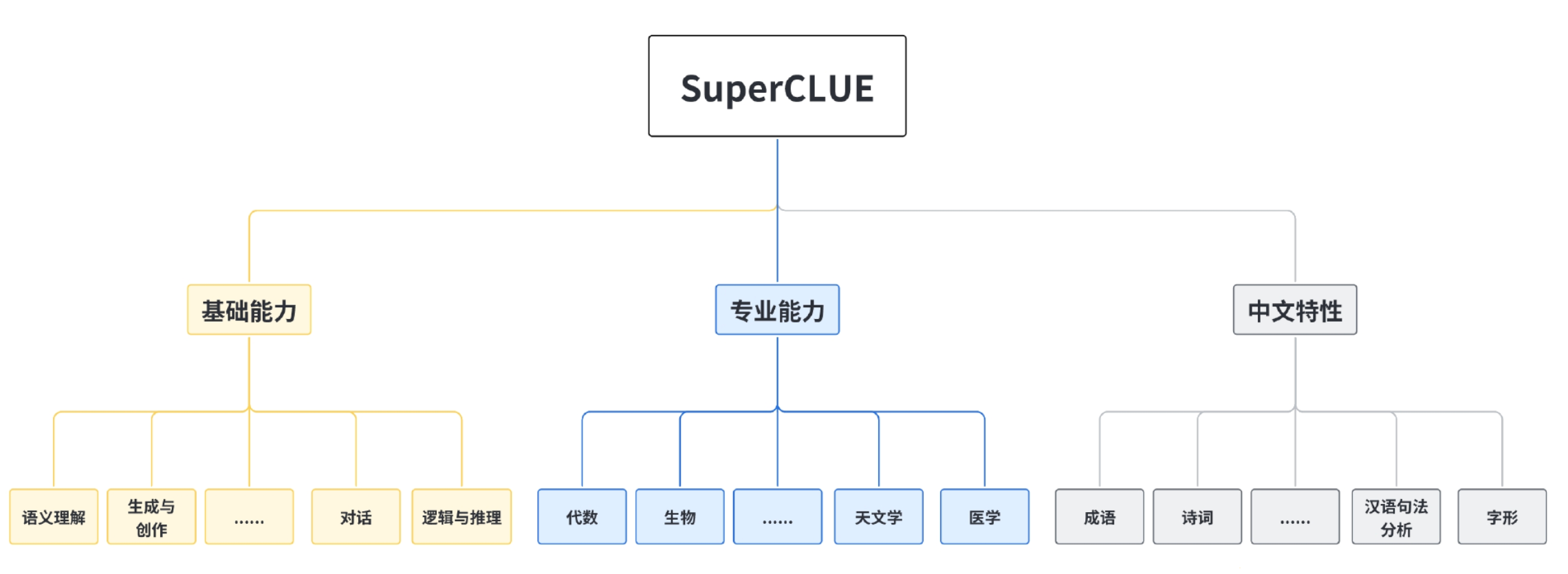
从测评角度来看,前面已经介绍了中文通用大模型的综合性测评基准 SuperCLUE,它对中文场景中的多个任务分支进行测试,涵盖基础能力、专业能力以及中文特性多个方面。每个任务分支又包含多个维度,例如语义理解、生成与创作、代数、生物、成语、诗词等。下图展示了这些维度的具体内容,SuperCLUE 每月都会更新测评结果,确保其反映大模型的最新表现。
尤其需要关注的是 SuperCLUE-RAG 检索增强生成测评,在 RAG 场景中,大模型的检索能力表现是核心。SuperCLUE 针对 RAG 应用场景进行了独立测试,具体评估了大模型在检索和生成过程中的表现,测试数据如下图所示(最新为2024 年 11月数据)。
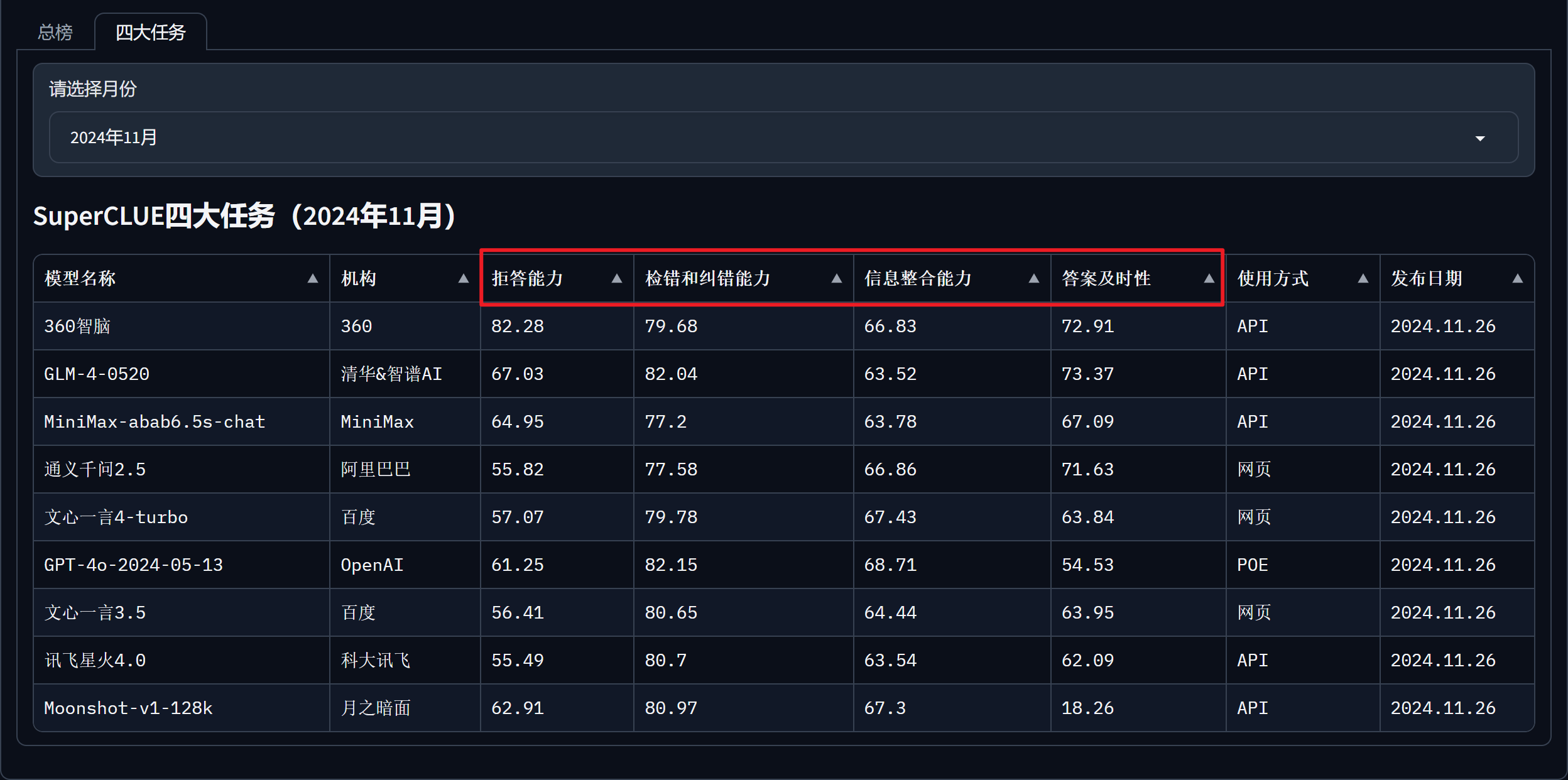
在 SuperCLUE 官网的 SuperCLUE-RAG 检索增强生成分支页面上,可以查看其总榜及四大基础任务的测评结果。选择模型时可以根据总分,以及模型在答案及时性、信息整合能力、拒答能力、检错和纠错能力等方面的表现,进行综合评估,作为场景选型参考。
其次,也是最重要的,我们需要根据实际应用场景来考量并选择适合的大模型,以下几个维度是关键:
1. 开源与闭源:开源模型适用于数据敏感性高或有严格合规要求的场景,通过自托管实现对数据的完全掌控,确保隐私与安全。而闭源模型则适合数据敏感度较低的应用场景,其维护与服务相对完善,能够降低运维复杂度。
2. 模型参数规模:大参数模型在复杂任务中的推理与生成能力较强,但并非所有应用场景都需要高精度模型。小参数模型(如 7B)在满足简单逻辑任务时,具备更优的响应速度、成本控制和资源利用效率。因此,模型规模应依据应用复杂性及算力预算进行合理匹配。
3. 国内与国外部署:模型选择还需考虑部署环境。如果应用主要在国内进行,虽然调用国外大模型的接口是可行的,但可能会遇到稳定性、网络延迟、注册认证、充值付费等方面的实际问题。此外,数据合规性是重要考量,尤其对于需要遵循国内隐私和数据安全法规的场景,选择国内大模型或本地化部署更为合适。综上所述,模型的选择应结合 RAG 应用场景的需求和限制,更好地选择合适的大模型以最大化其效果。
选择建议:
1. 闭源模型: 通义千问、文心一言、混元大模型、豆包大模型和 Kimi Chat 等旗舰模型实际差异不大,取决于成本。
2. 开源模型: 根据需求可以在千问系列,deepseek系列,百川系列,GLM系列这几个中选择。