RAG检索流程(二):重排序
重排序(Reranking)的目的是将混合检索的结果进行整合,并将与用户问题语义最契合的结果排在前列。
下图中仅仅混合检索,由于缺乏有效的排序,我们期望的结果位于第一和第四位,尽管依然可以被检索到,但理想情况下,如果检索方式更为精确,该结果应该被优先排序在前两位。
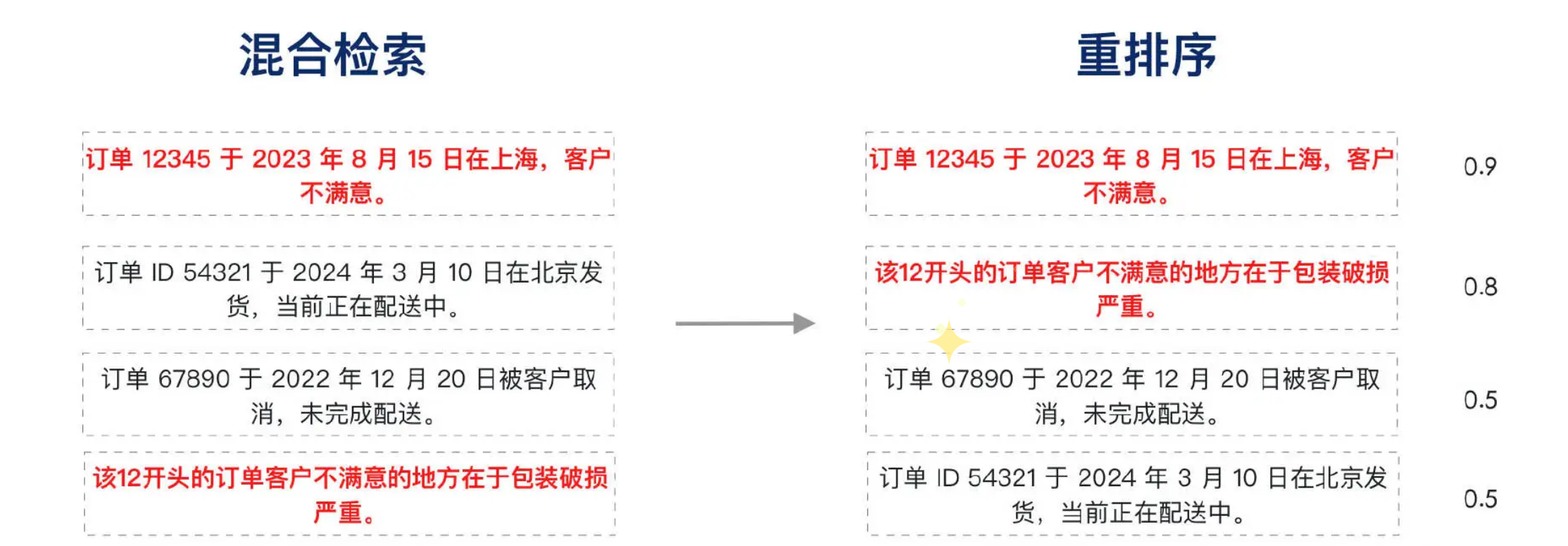
在这个案例中,我们通过重排序技术成功找到了与问题语义最契合的结果。系统评分显示,“订单 12345 于 2023 年 8 月 15 日在上海,客户不满意。”与“该 12 开头的订单客户不满意的地方在于包装破损严重。”这两个文档块的相关性分别为 0.9 和 0.8,排序为第一和第二位。
重排序技术在检索系统中扮演着至关重要的角色。即使检索算法已经能够捕捉到所有相关的结果,重排序过程依然不可或缺。它确保最符合用户意图和查询语义的结果优先展示,从而提升用户的搜索体验和结果的准确性。通过重排序,检索系统不仅能找到相关信息,还能智能地将最重要的信息呈现在用户面前。
为什么要使用重排序技术?
在 RAG 检索流程中,重排序技术(Reranking)通过对初始检索结果进行重新排序,改善检索结果的相关性,为生成模型提供更优质的上下文,从而提升整体 RAG 系统的效果。
尽管向量检索技术能够为每个文档块生成初步的相关性分数,但引入重排序模型仍然至关重要。向量检索主要依赖于全局语义相似性,通过将查询和文档映射到高维语义空间中进行匹配。然而,这种方法往往忽略了查询与文档具体内容之间的细粒度交互。
重排序模型大多是基于双塔或交叉编码架构的模型,在此基础上进一步计算更精确的相关性分数,能够捕捉查询词与文档块之间更细致的相关性,从而在细节层面上提高检索精度。因此,尽管向量检索提供了有效的初步筛选,重排序模型则通过更深入的分析和排序,确保最终结果在语义和内容层面上更紧密地契合查询意图,实现了检索质量的提升。
2023 年,Microsoft Azure AI 发布了《Azure 认知搜索:通过混合检索和排序能力超越向量搜索》一文。这篇文章对在 LLM RAG 应用中引入混合检索和重排序技术进行了全面的实验数据评估,并量化了这些技术组合在提升文档召回率和准确性方面的显著效果。实验结果表明,在多个数据集和多种检索任务中,混合检索与重排序的组合均取得了最佳表现。
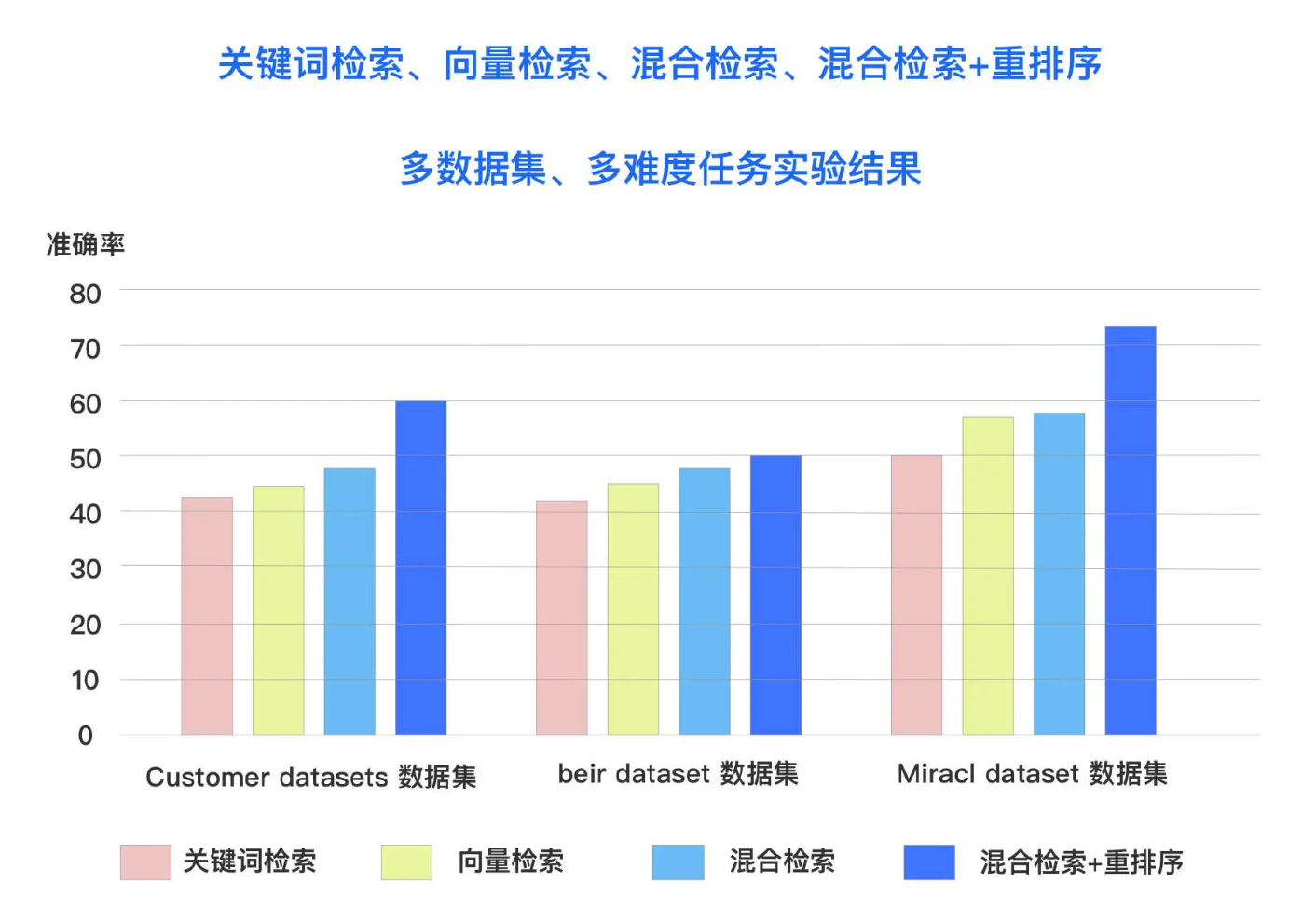
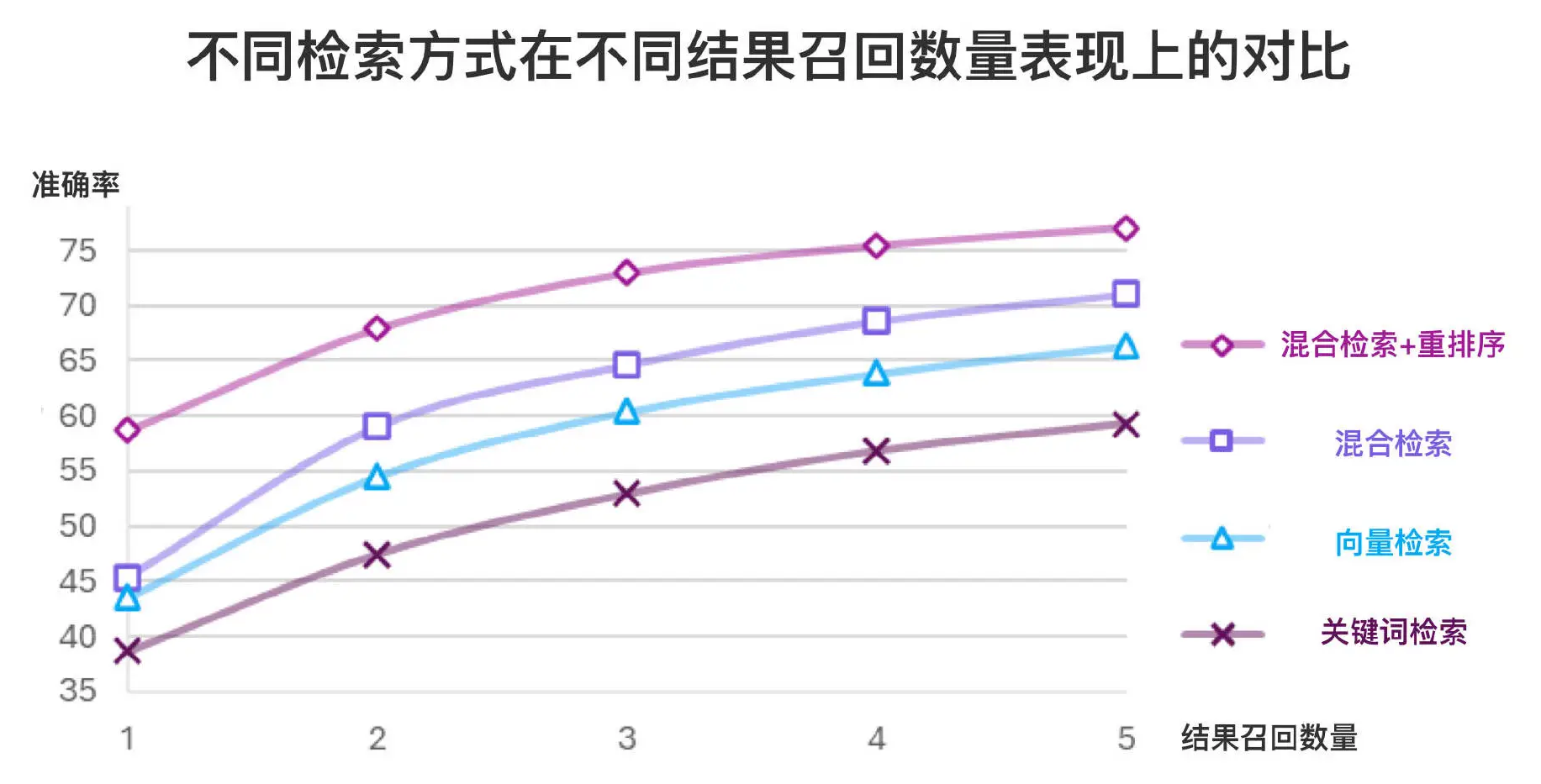
以下是使用重排序技术的几个优势:
-
优化检索结果
在 RAG 系统中,初始的检索结果通常来自于向量搜索或基于关键词的检索方法。然而,这些初始检索结果可能包含大量的冗余信息或与查询不完全相关的文档。通过重排序技术,我们可以对这些初步检索到的文档进行进一步的筛选和排序,将最相关、最重要的文档置于前列。
-
增强上下文相关性
RAG 系统依赖于检索到的文档作为生成模型的上下文。因此,上下文的质量直接影响生成的结果。重排序技术通过重新评估文档与查询的相关性,确保生成模型优先使用那些与查询最相关的文档,从而提高了生成内容的准确性和连贯性。
-
应对复杂查询
对于复杂的查询,初始检索可能会返回一些表面上相关但实际上不太匹配的文档。重排序技术可以根据查询的复杂性和具体需求,对这些结果进行更细致的分析和排序,优先展示那些能够提供深入见解或关键信息的文档。
重排序模型 Reranking Model
RAG 流程有两个概念,粗排和精排。粗排检索效率较快,但是召回的内容并不一定强相关。而精排效率较低,因此适合在粗排的基础上进行进一步优化。精排的代表就是重排序(Reranking)。
**重排序模型(Reranking Model)**查询与每个文档块计算对应的相关性分数,并根据这些分数对文档进行重新排序,确保文档按照从最相关到最不相关的顺序排列,并返回前 top-k 个结果。
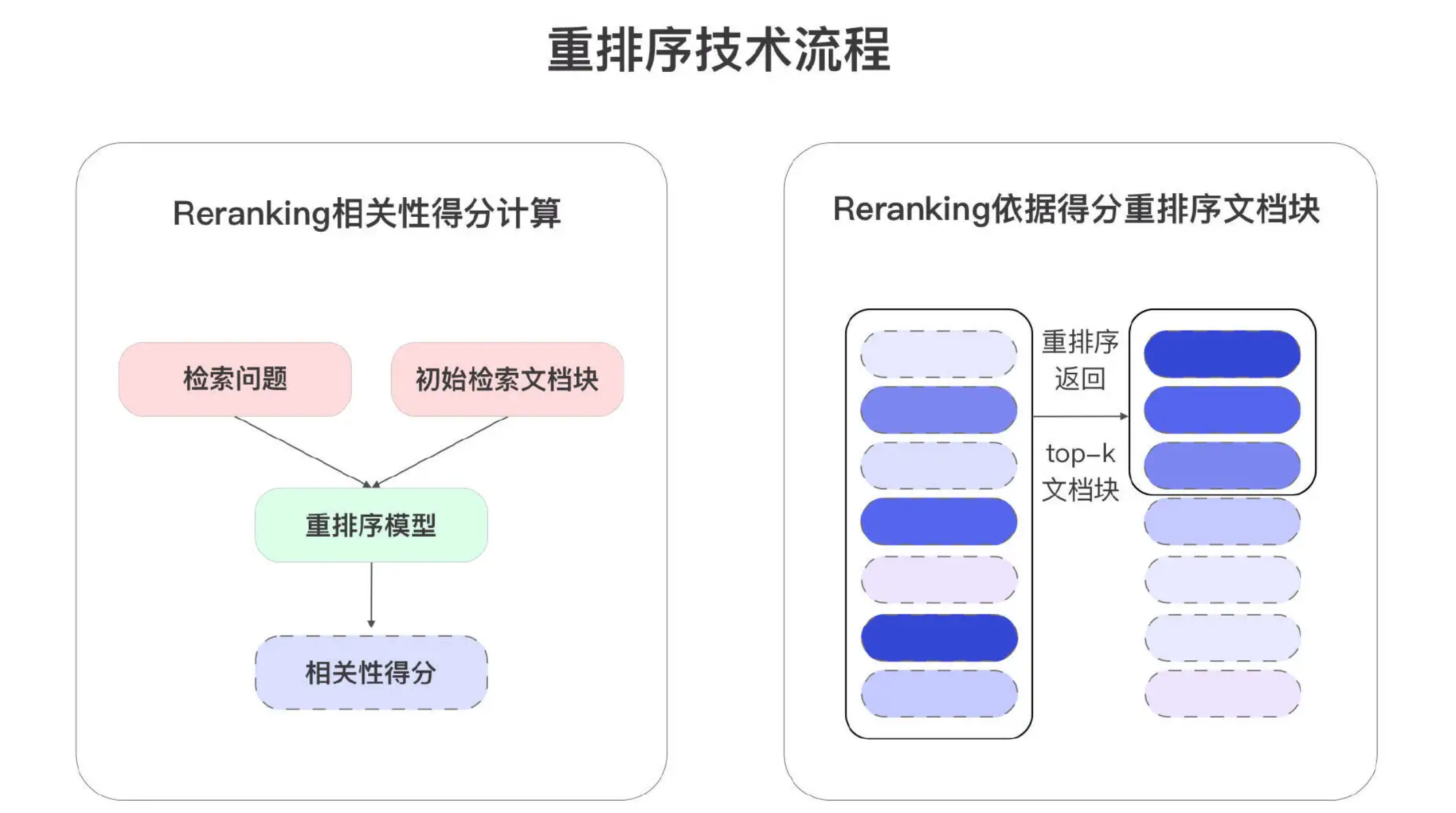
与嵌入模型不同,重排序模型将用户的查询(Query)和文档块作为输入,直接输出相似度评分,而非生成嵌入向量。目前,市面上可用的重排序模型并不多,商用的有 Cohere,开源的有 BGE、Sentence、Mixedbread、T5-Reranker 等,甚至可以使用指令(Prompt)让大模型(GPT、Claude、通义千问、文心一言等)进行重排,大模型指令参考如下:
1 | 以下是与查询 {问题} 相关的文档块: |
在生产环境中使用重排序模型会面临资源和效率问题,包括计算资源消耗高、推理速度慢以及模型参数量大等问题。这些问题主要源于重排序模型在对候选项进行精细排序时,因其较大参数量而导致的高计算需求和复杂耗时的推理过程,从而对 RAG 系统的响应时间和整体效率产生负面影响。因此,在实际应用中,需要根据实际资源情况,在精度与效率之间进行平衡。
重排序技术实战
在实战中,我们使用来自北京人工智能研究院 BGE 的 bge-reranker-v2-m3 作为 RAG 项目的重排序模型,这是一种轻量级的开源和多语言的重排序模型。更多模型相关信息参考,可访问https://huggingface.co/BAAI/bge-reranker-v2-m3
这部分的代码文件为 rag_lesson_6。可到我的 Github 托管项目(https://github.com/hfhfn/rag_learning)下载,或使用 git clone https://github.com/hfhfn/rag_learning.git ,拉取最新代码.