RAG检索流程(一):混合检索
为什么需要混合检索?
我们本节课正式开始讲解 RAG 检索流程。当前主流的 RAG 检索方式主要采用向量检索(Vector Search),通过语义相似度来匹配文本切块。这种方法在我们之前的课程中已经深入探讨过了。然而,向量检索并非万能,它在某些场景下无法替代传统关键词检索的优势。
例如,当你需要精准搜索某个订单 ID、品牌名称或地址,或者搜索特定人物或物品的名字(如伊隆·马斯克、iPhone 15)时,向量检索的准确性往往不如关键词检索。此外,当用户输入的问题非常简短,仅包含几个单词时,比如搜索缩写词或短语(如 RAG、LLM),语义匹配的效果也可能不尽理想。
这些正是传统关键词检索的优势所在。关键词检索(Keyword Search)在几个场景中表现尤为出色:精确匹配,如产品名称、姓名、产品编号;少量字符的匹配,用户习惯于输入几个关键词,而少量字符进行向量检索时效果可能较差;以及低频词汇的匹配,低频词汇往往承载了关键意义,如在“你想跟我去喝咖啡吗?”这句话中,“喝”“咖啡”比“你”“吗”更具重要性。
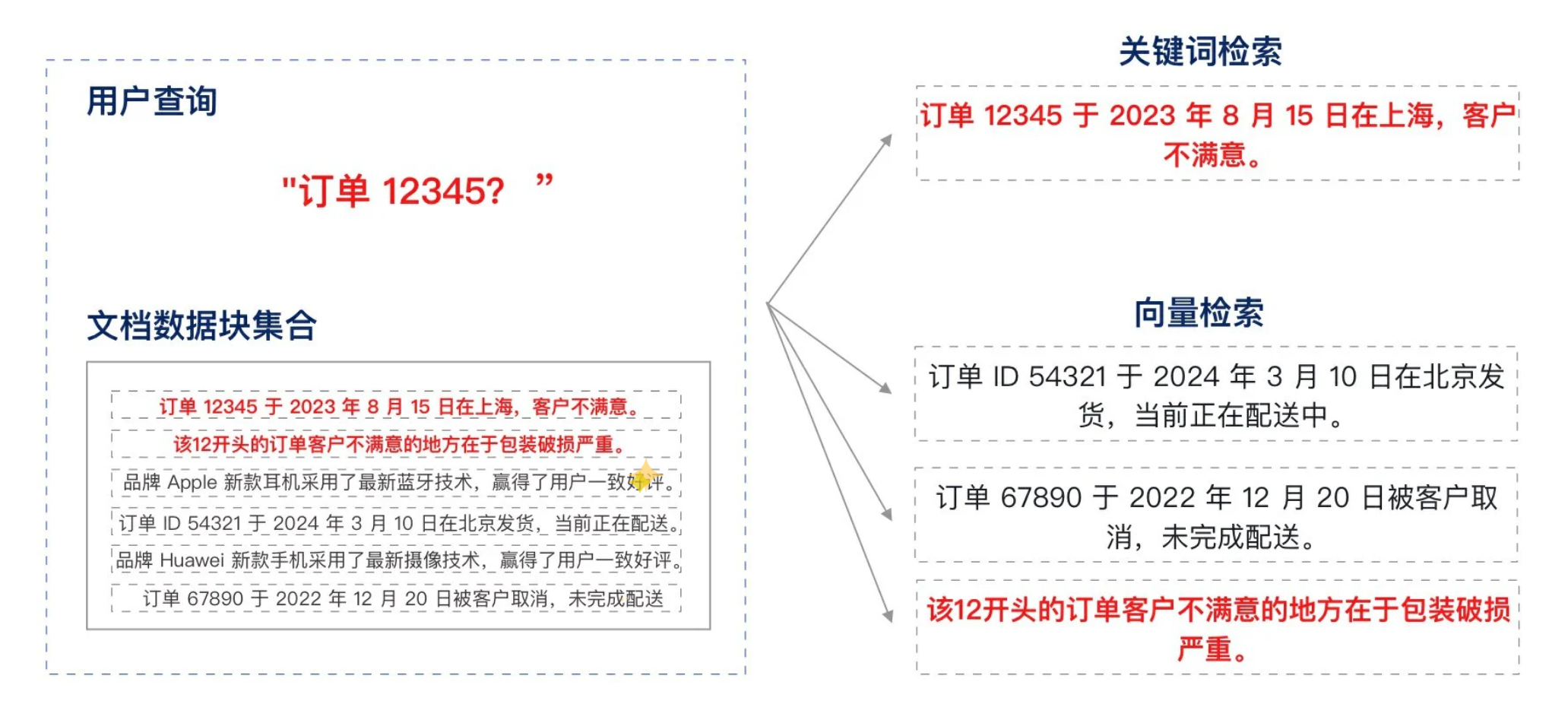
在上述案例中,虽然依靠关键词检索可以精确找到与“订单 12345”匹配的特定信息,但它无法提供与订单相关的更广泛上下文。另一方面,语义匹配虽然能够识别“订单”和“配送”等相关概念,但在处理具体的订单 ID 时,往往容易出错。
混合检索(Hybrid Search)通过结合关键词检索和语义匹配的优势,可以首先利用关键词检索精确定位到“订单 12345”的信息,然后通过语义匹配扩展与该订单相关的其他上下文或客户操作的信息,例如“12 开头的订单、包装破损严重”等。这样不仅能够获取精确的订单详情,还能获得与之相关的额外有用信息。
在 RAG 检索场景中,首要目标是确保最相关的结果能够出现在候选列表中。向量检索和关键词检索各有其独特优势,混合检索通过结合这多种检索技术,弥补了各自的不足,提供了一种更加全面的搜索方案。
混合检索(多路召回)
混合检索是指在检索过程中同时采用多种检索方式,并将各类检索结果进行融合,从而得到最终的检索结果。混合检索的优势在于能够充分利用不同检索方式的优点,弥补各自的不足,从而提升检索的准确性和效率。下图展示了混合检索的流程:
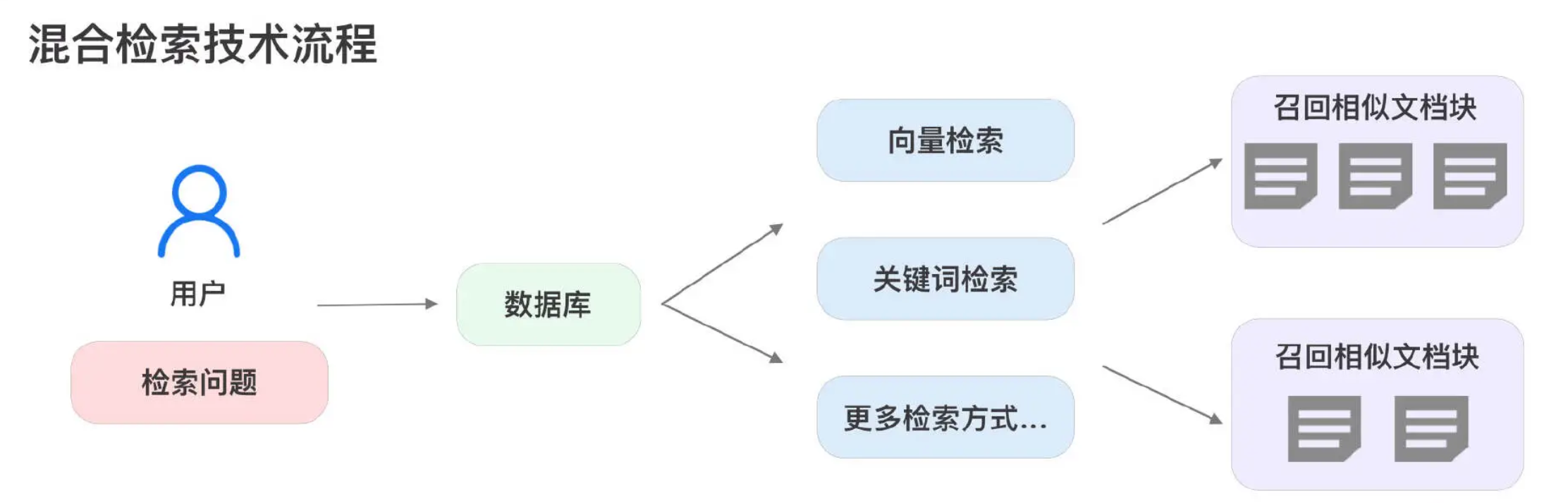
混合检索实际上并没有严格限定必须包含哪几种检索方式。这里我们以向量检索和关键词检索的组合为例,但实际上可以包含多种检索方式的组合。如果我们将其他搜索算法结合在一起,也同样可以称为“混合检索”。例如,可以将**知识图谱(graphRAG)**技术用于检索实体关系,并与向量检索技术相结合。
更多的 RAG 检索方式还包括多重提问检索、上下文压缩检索、集成检索、多向量检索、自查询检索等,每种检索方式说明如下:

上述方法均包含在 LangChain 的检索器模块 langchain.retrievers 中,具体详情可以查看 LangChain 检索器站点。
混合检索后,我们需要对多个检索方式的检索结果进行综合排名。下节课会详细讲解重排序技术,这里我们简单了解一种更简单的方法来排序,称为递归折减融合(Reciprocal Rank Fusion, RRF)排序。RRF 是一种把来自不同检索方法的排名结果结合起来的技巧。它的基本思想是,如果一个文档在不同的检索结果中都排得比较靠前,那么它在综合排名中就应该得到更高的位置。
相比于复杂的重排序技术,RRF 的操作更加简单,不需要对每种检索结果进行复杂的调整或计算。它通过直接考虑文档在不同方法中的排名,快速生成一个合理的综合排名。这种方法非常适合那些需要快速融合多个检索结果的场景,短时间内得到一个有参考价值的排序。
选择何种检索技术,取决于开发者需要解决什么样的问题,系统的性能要求、数据的复杂性以及用户的搜索习惯等。针对具体需求选择合适的检索技术,能够最大化地提升 RAG 系统的效率和准确性。
混合检索技术实战
在实战中,我们使用 rank_bm25 作为 RAG 项目的关键词搜索技术。BM25 是一种强大的关键词搜索算法,通过分析词频(TF)和逆向文档频率(IDF)来评估文档与查询的相关性。具体来说,BM25 检查查询词在文档中的出现频率,以及该词在所有文档中出现的稀有程度。如果一个词在特定文档中频繁出现,但在其他文档中较少见,那么 BM25 会将该文档评为高度相关。
此外,BM25 还通过调整文档长度的影响,防止因文档长度不同而导致的词频偏差。正是这种结合了词频和文档长度平衡的机制,使得 BM25 在关键词搜索中能够提供精准的检索结果,在 RAG 项目中尤为有效。
需要安装的依赖库:
1 | pip install -U pip jieba rank_bm25 chromadb langchain langchain_community sentence-transformers unstructured pdfplumber python-docx python-pptx markdown openpyxl pandas -i https://pypi.tuna.tsinghua.edu.cn/simple |
代码内容:
- 引入了 rank_bm25 库中的 BM25Okapi 类,用于实现 BM25 算法的检索功能。
- 引入了 jieba 库,用于对中文文本进行分词处理,这对于 BM25 算法处理中文文本起关键作用。
- 在 retrieval_process 方法中,从 Chroma 的 collection 中提取所有存储的文档内容,并使用 jieba 对这些文档进行中文分词,将分词结果存储为 tokenized_corpus,为后续的 BM25 检索做准备。
- 利用分词后的文档集合实例化 BM25Okapi 对象,并对查询语句进行分词处理。
- 计算查询语句与每个文档之间的 BM25 相关性得分 (bm25_scores),然后选择得分最高的前 top_k 个文档,并提取这些文档的内容。
- 返回合并后的全部检索结果,包含向量检索和 BM25 检索的结果。(下节内容会引入重排序,这里只做简单顺序合并)