RAG索引(三):嵌入(Embedding)技术
嵌入模型(Embedding Model)负责将文本数据映射到高维向量空间中,将输入的文档片段转换为对应的嵌入向量(embedding vectors)。这些向量捕捉了文本的语义信息,并被存储在向量库(VectorStore)中,以便后续检索使用。用户查询(Query)同样通过嵌入模型的处理生成查询嵌入向量,这些向量用于在向量数据库中通过向量检索(Vector Retrieval)匹配最相似的文档片段。根据不同的场景需求,评估并选择最优的嵌入模型,以确保 RAG 的检索性能符合要求。

-
什么是Embedding嵌入?
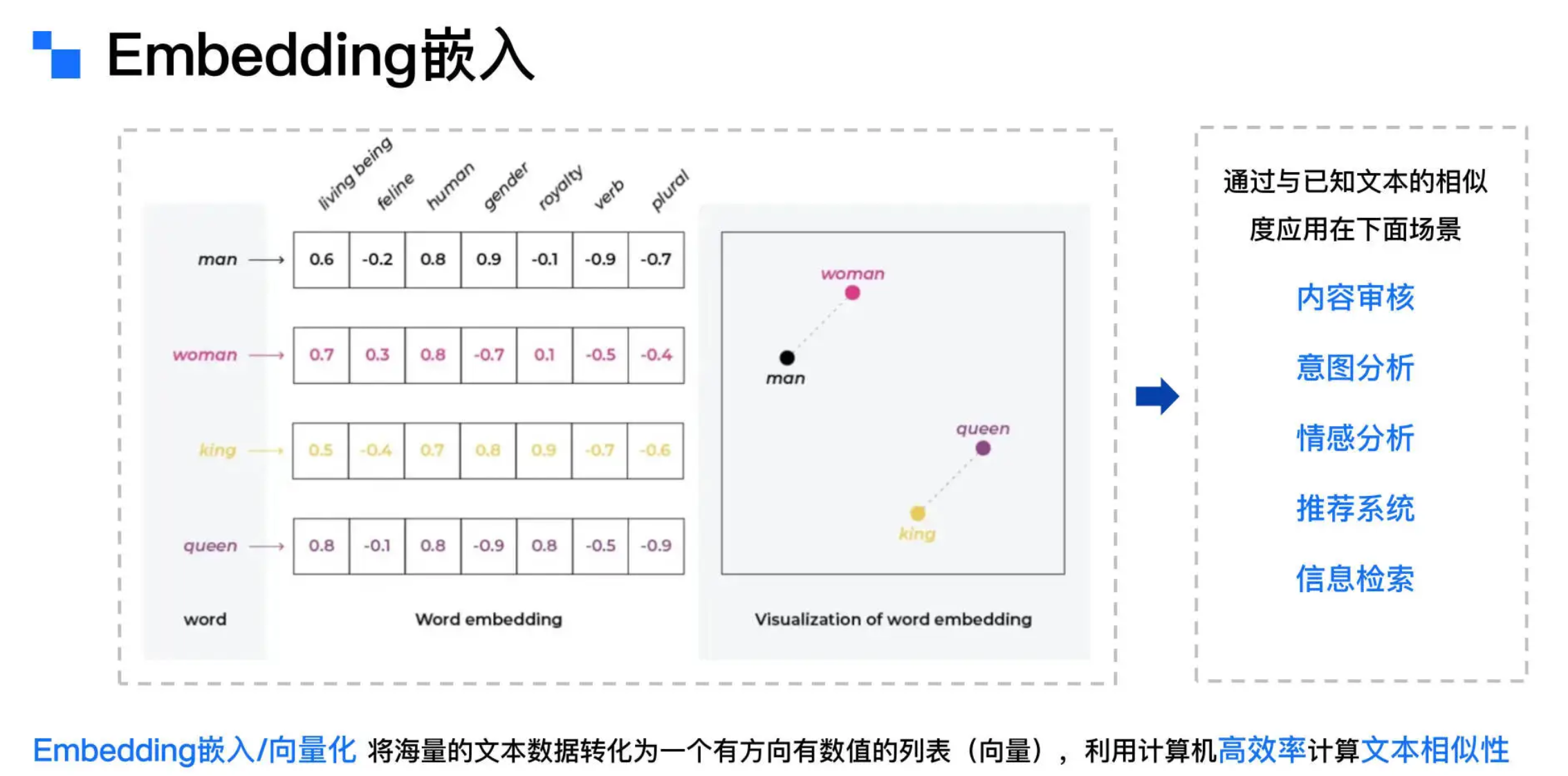
- Embedding 嵌入是指将文本、图像、音频、视频等形式的信息映射为高维空间中的密集向量表示。这些向量在语义空间中起到坐标的作用,捕捉对象之间的语义关系和隐含的意义。通过在向量空间中进行计算(例如余弦相似度),可以量化和衡量这些对象之间的语义相似性。
- 在具体实现中,嵌入的每个维度通常对应文本的某种特征,例如性别、类别、数量等。通过多维度的数值表示,计算机能够理解并解析文本的复杂语义结构。例如,“man”和“woman”在描述性别维度上具有相似性,而“king”和“queen”则在性别和王室身份等维度上表现出相似的语义特征。
- 向量是一组在高维空间中定义点的数值数组,而嵌入则是将信息(如文本)转化为这种向量表示的过程。这些向量能够捕捉数据的语义及其他重要特征,使得语义相近的对象在向量空间中彼此邻近,而语义相异的对象则相距较远。向量检索(Vector Retrieval)是一种基于向量表示的搜索技术,通过计算查询向量与已知文本向量的相似度来识别最相关的文本数据。向量检索的高效性在于,它能在大规模数据集中快速、准确地找到与查询最相关的内容,这得益于向量表示中蕴含的丰富语义信息。
-
-
Embedding Model 嵌入模型
- 自 2013 年以来,word2vec、GloVe、fastText 等嵌入模型通过分析大量文本数据,学习得出单词的嵌入向量。近年来,随着 transformer 模型的突破,嵌入技术以惊人的速度发展。BERT、RoBERTa、ELECTRA 等模型将词嵌入推进到上下文敏感的阶段。这些模型在为文本中的每个单词生成嵌入时,会充分考虑其上下文环境,因此同一个单词在不同语境下的嵌入向量可以有所不同,从而大大提升了模型理解复杂语言结构的能力。
- 在 RAG 系统中,Embedding Model 嵌入模型扮演着关键角色,负责将文本数据映射到高维向量空间,以便高效检索和处理。具体而言,Embedding Model 将输入的文档片段(Chunks)和查询文本(Query)转换为嵌入向量(Vectors),这些向量捕捉了文本的语义信息,并可在向量空间中与其他嵌入向量进行比较。
- 在 RAG 流程中,文档首先被分割成多个片段,每个片段随后通过 Embedding Model 进行嵌入处理。生成的文档嵌入向量被存储在 VectorStore 中,供后续检索使用。用户查询会通过 Embedding Model 转换为查询嵌入向量,这些向量用于在向量数据库中匹配最相似的文档片段,最终组合生成指令(Prompt),大模型生成回答。
-
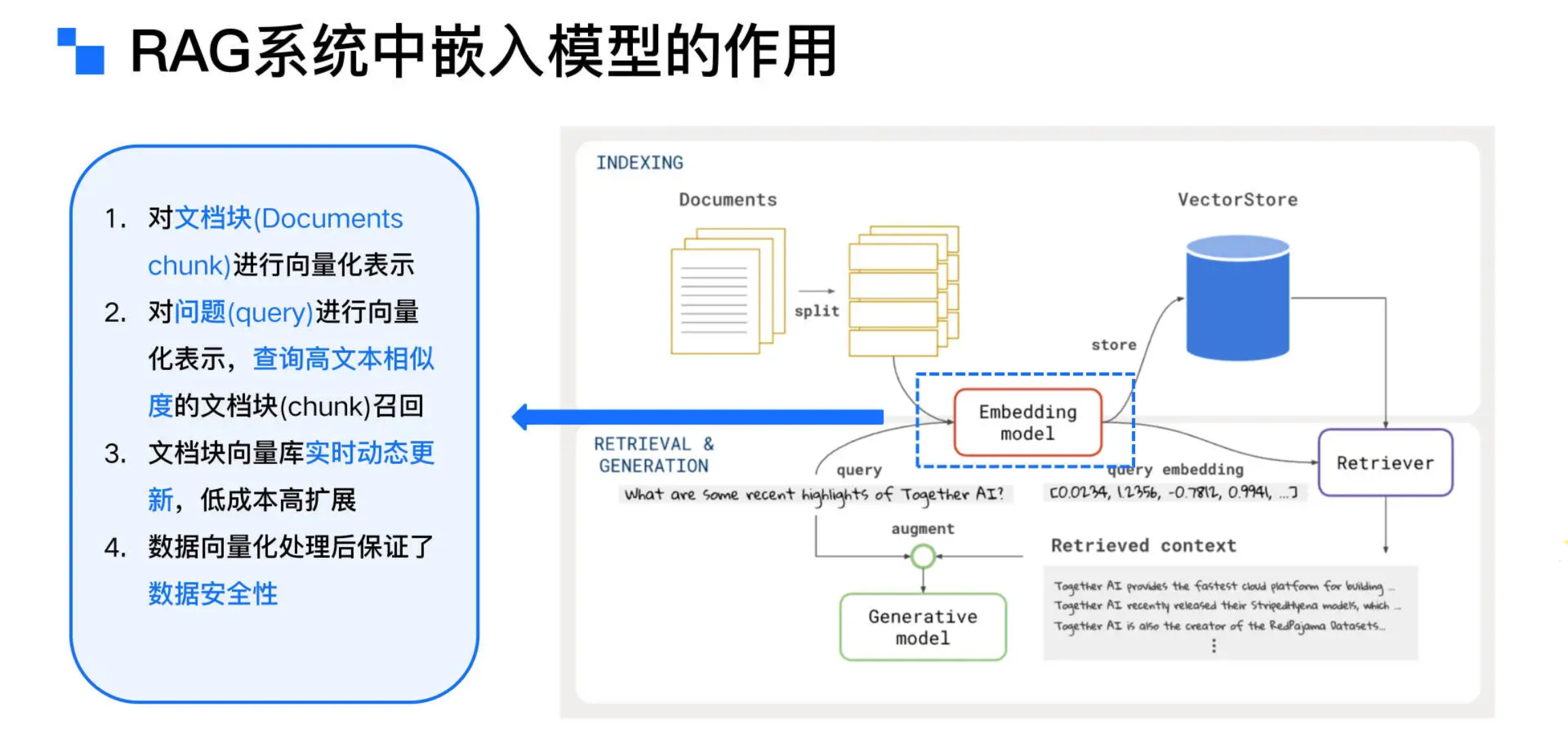
- 正如图中所示,嵌入模型是 RAG 流程的核心。既然如此重要,市面上有非常多的嵌入模型,我们该如何为我们的业务场景选择最合适的嵌入模型呢?
-
Embedding Model 嵌入模型评估与选择
- 在选择适合的嵌入模型时,需要综合考虑多个因素,包括特定领域的适用性、检索精度、支持的语言、文本块长度、模型大小以及检索效率等因素。同时以广泛受到认可的 **MTEB(Massive Text Embedding Benchmark)和 C-MTEB(Chinese Massive Text Embedding Benchmark)**榜单作为参考,通过涵盖分类、聚类、语义文本相似性、重排序和检索等多个数据集的评测,开发者可以根据不同任务的需求,评估并选择最优的向量模型,以确保在特定应用场景中的最佳性能。
-
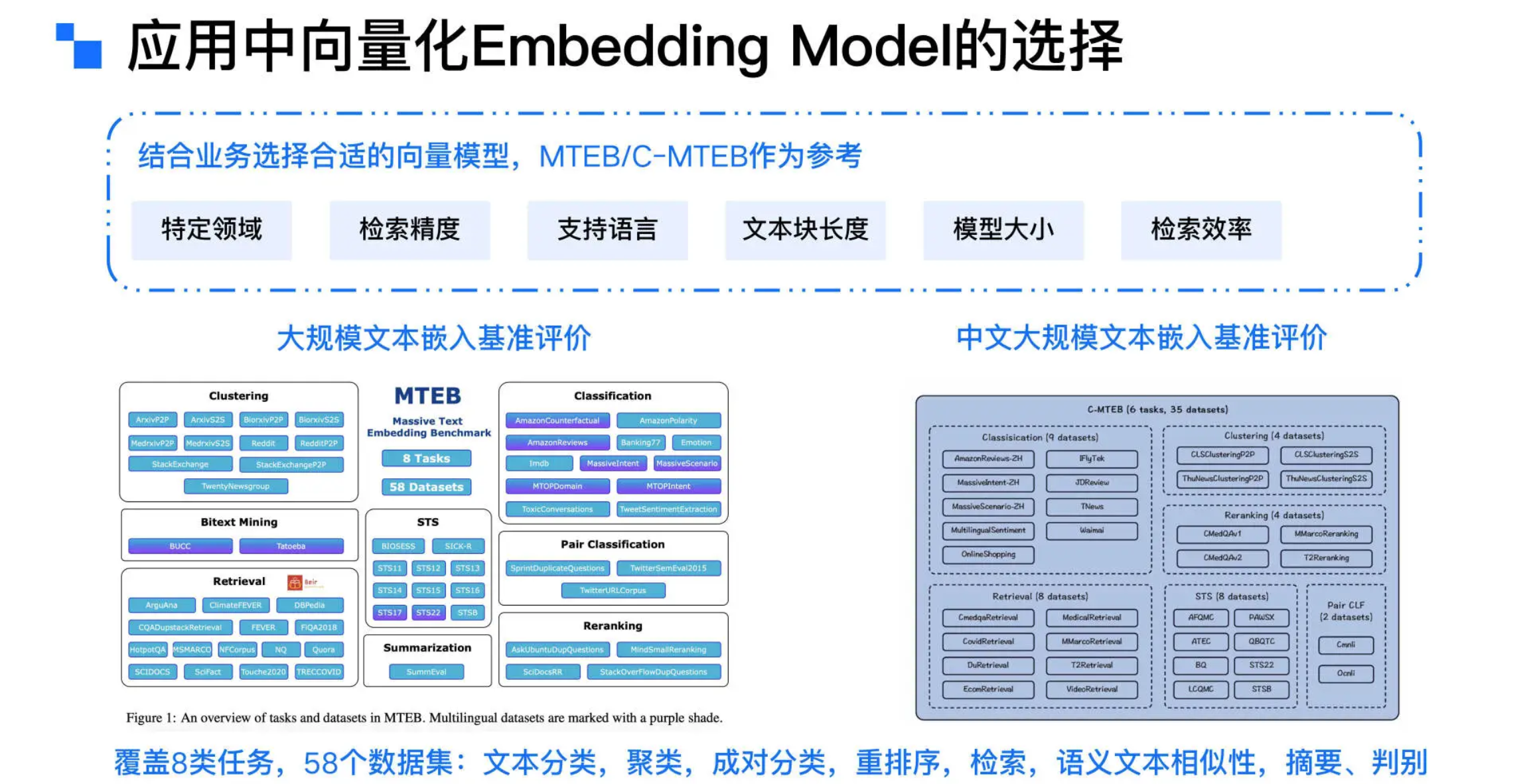
- MTEB & C-MTEB 榜单
-
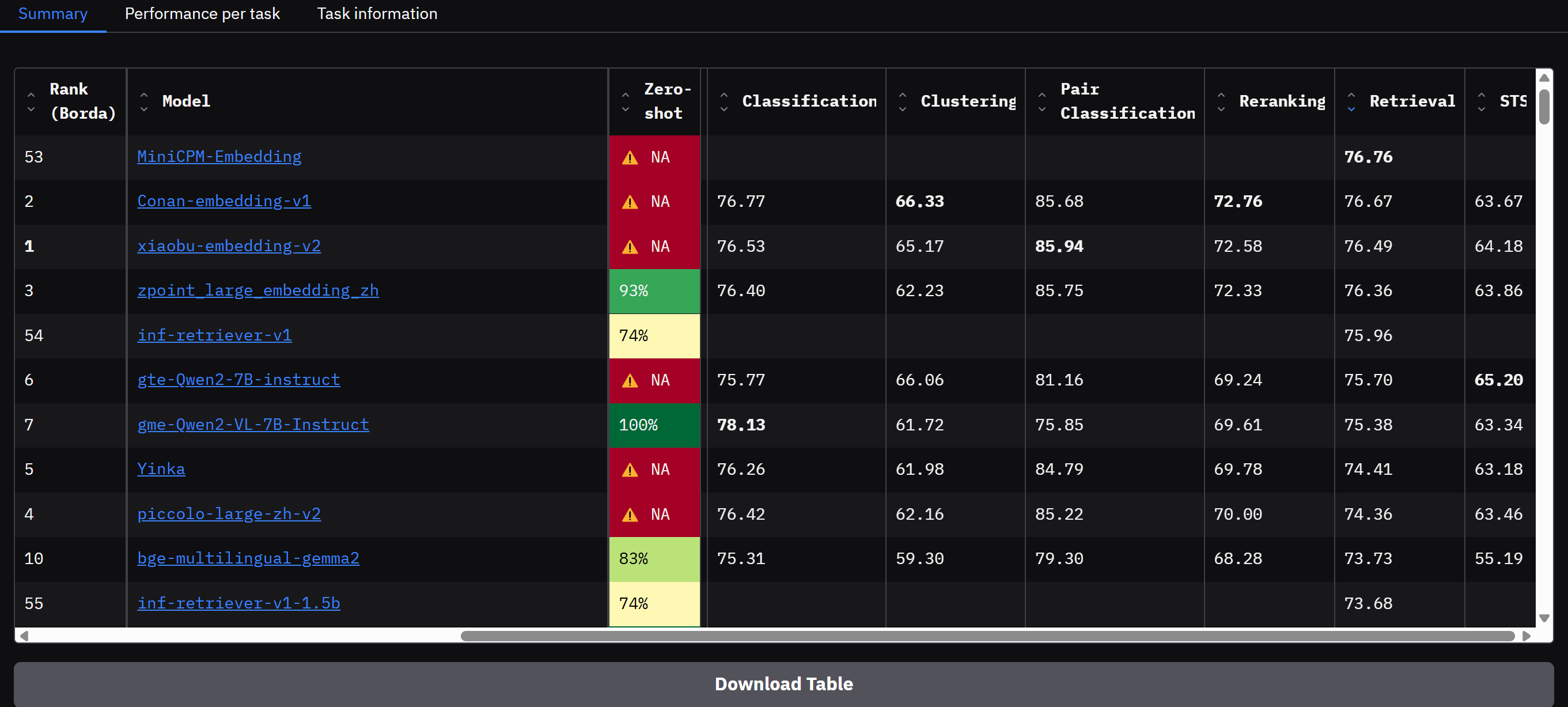
- 榜单每日更新,可以切换语言为 中文,可以看到中文嵌入模型的排名。由于 RAG 是一项检索任务,我们需要按“Retrieval Average”(检索平均值)列对排行榜进行排序,图中显示的就是检索任务效果排序后的结果。在检索任务中,我们需要在榜单顶部看到最佳的检索模型,并且专注于以下几个关键列:
- Retrieval Average 检索平均值:较高的检索平均值表示模型更擅长在检索结果列表中将相关项目排在较高的位置,检索效果更好。
- Model Size 模型大小:模型的大小(以 GB 为单位)。虽然检索性能随模型大小而变化,但要注意,模型大小也会对延迟产生直接影响。因此,在选择模型时,建议筛选掉那些在硬件资源有限的情况下不可行的过大模型。在生产环境中,性能与效率之间的权衡尤为重要。
- Max Tokens 最大 Token 数:可压缩到单个文本块中的最大 Token 数。因为文档块我们希望不要过大而降低目标信息块的精准度,因此,即使最大 tokens 数为 512 的模型在大部分场景下也足够使用。
- Embedding Dimensions:嵌入向量的维度。越少的嵌入维度提供更快的推理速度,存储效率更高,而更多的维度可以捕获数据中的细微特征。我们需要在模型的性能和效率之间取得良好的权衡。
- 实验至关重要,在排行榜上表现良好的模型不一定在你的任务上表现良好,试验各种高得分的模型至关重要。我们参考 MTEB 排行榜,选择多个适合我们场景的嵌入模型作为备选,并在我们的业务场景数据集上进行评估测试,以选出最适合我们 RAG 系统的嵌入模型。
-
Embedding Model 技术实战
-
我们可以使用 SentenceTransformers 作为加载嵌入模型的 Python 模块。
-
SentenceTransformers(又名 SBERT)是一个用于训练和推理文本嵌入模型的 Python 模块,可以在 RAG 系统中计算嵌入向量。使用 SentenceTransformers 进行文本嵌入转换非常简单:只需导入模块库、加载模型,并调用 encode 方法即可。执行时,SentenceTransformers 会自动下载相应的模型库,当然也可以手动下载并指定模型库的路径。所有可用的模型都可以在 SentenceTransformers 模型库 查看,超过 8000 个发布在 Hugging Face 上的嵌入模型库可以被使用。
-
在中文领域,智源研究院的 BGE 系列模型 是较为知名的开源嵌入模型,在 C-MTEB 上表现出色。BGE 系列目前包含 23 个嵌入模型,涵盖多种维度、多种最大 Token 数和模型大小,用户可以根据需求进行测试和使用。
-
load_embedding_model 方法中使用 SentenceTransformer 加载嵌入模型代码:
1
2
3
4
5# 绝对路径:SentenceTransformer读取绝对路径下的bge-large-zh-v1.5模型,如需使用其他模型,下载其他模型,并且更换绝对路径即可
embedding_model = SentenceTransformer(os.path.abspath('data/bge-large-zh-v1.5'))
# 自动下载:SentenceTransformer库自动下载BAAI/bge-large-zh-v1.5模型,如需下载其他模型,输入其他模型名称即可
# embedding_model = SentenceTransformer('BAAI/bge-large-zh-v1.5') -
indexing_process 方法中将文本转化为嵌入向量代码:
1
2
3
4
5# 文本块转化为嵌入向量列表,normalize_embeddings表示对嵌入向量进行归一化,用于后续流程准确计算向量相似度
embeddings = []
for chunk in all_chunks:
embedding = embedding_model.encode(chunk, normalize_embeddings=True)
embeddings.append(embedding)
-
-
总结
- 嵌入技术将文本数据映射到高维向量空间中,捕捉其语义信息,支持向量检索,从而在大规模数据中快速识别与查询最相关的文档片段。在选择嵌入模型时,需要综合考虑特定领域的适用性、检索精度、支持的语言、文本块长度、模型大小以及检索效率等因素。
- 通过参考 MTEB 和 C-MTEB 的评测榜单,可以评估多个高得分的模型,并在具体的业务场景中进行测试,最终选择最适合该场景的嵌入模型。同时,使用 SentenceTransformers Python 模块可以简化嵌入模型的加载和嵌入计算,进而高效率集成测试。