RAG索引(二):分块策略
文档数据(Documents)经过解析后,通过分块技术将信息内容划分为适当大小的文档片段(chunks),从而使 RAG 系统能够高效处理和精准检索这些片段信息。
选择适合特定场景的分块策略是提升 RAG 系统召回率的关键。
-
为什么说分块很重要?
-
分块的目标在于确保每个片段在保留核心语义的同时,具备相对独立的语义完整性,从而使模型在处理时不必依赖广泛的上下文信息,增强检索召回的准确性。
-
分块的重要性在于它直接影响 RAG 系统的生成质量。首先,合理的分块能够确保检索到的片段与用户查询信息高度匹配,避免信息冗余或丢失。
-
好的分块有助于提升生成内容的连贯性,精心设计的独立语义片段可以降低模型对上下文的依赖,从而增强生成的逻辑性与一致性。
-
分块策略的选择还会影响系统的响应速度与效率,模型能够更快、更准确地处理和生成内容。
-
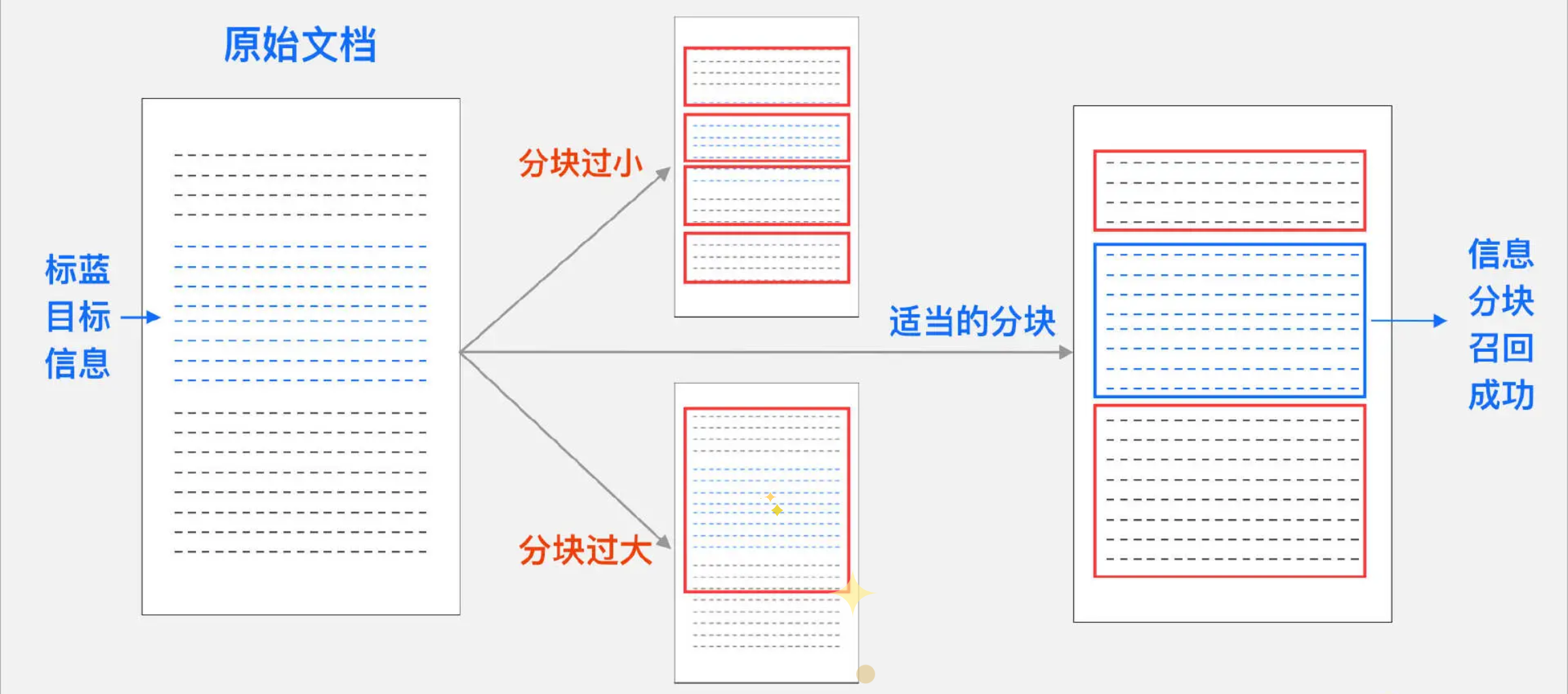
分块策略最大的挑战在于确定分块的大小。
- 如果片段过大,可能导致向量无法精确捕捉内容的特定细节并且计算成本增加;
- 若片段过小,则可能丢失上下文信息,导致句子碎片化和语义不连贯。
- 较小的块适用于需要细粒度分析的任务,例如情感分析,能够精确捕捉特定短语或句子的细节。
- 更大的块则更为合适需要保留更广泛上下文的场景,例如文档摘要或主题检测。
-
-
-
分块策略
-
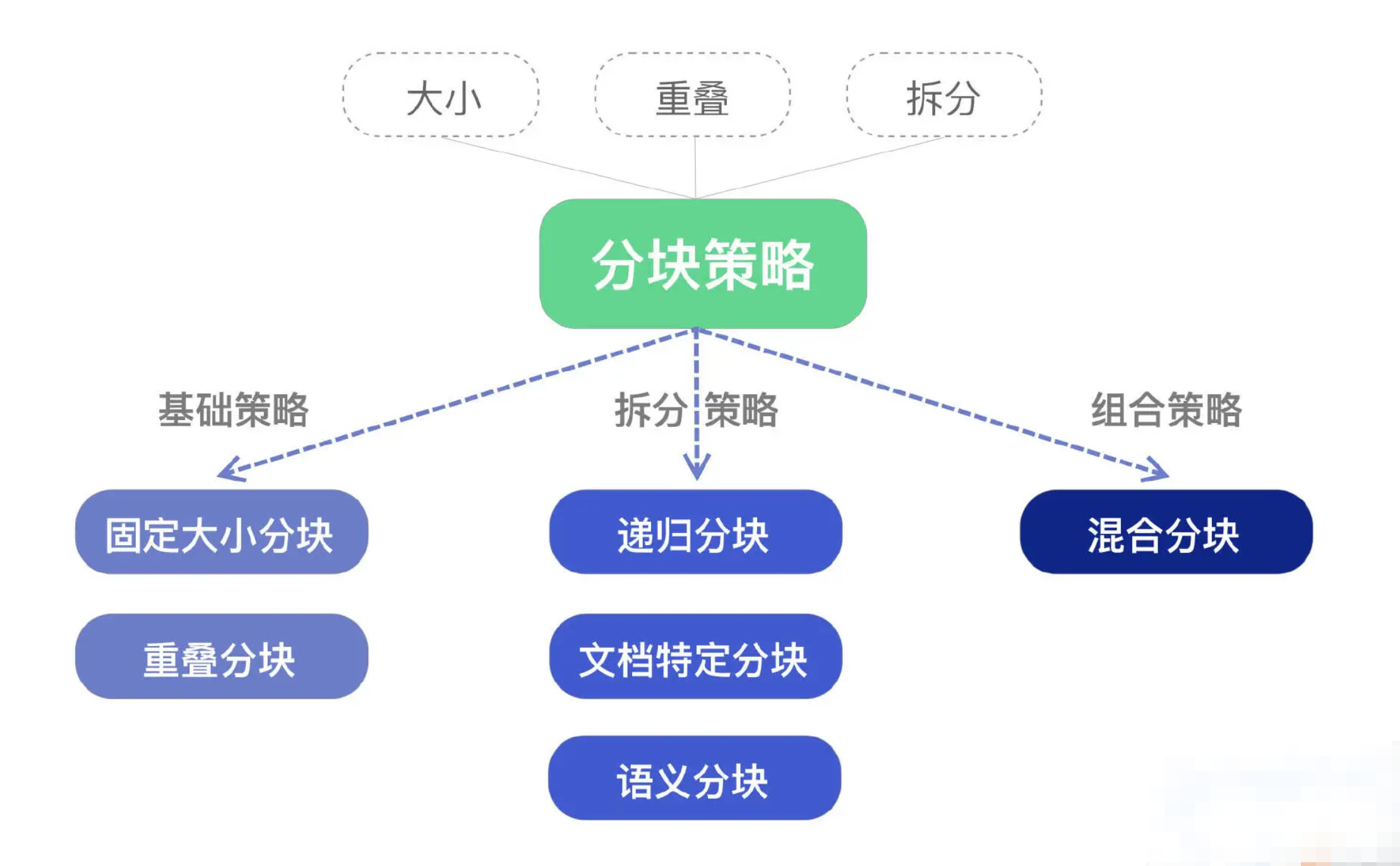
多种分块策略从本质上来看,由以下三个关键组成部分构成:
- 大小:每个文档块所允许的最大字符数。
- 重叠:在相邻数据块之间,重叠字符的数量。
- 拆分:通过段落边界、分隔符、标记,或语义边界来确定块边界的位置。
-
上述三个组成部分共同决定了分块策略的特性及其适用场景。基于这些组成部分,常见的分块策略包括:
- 固定大小分块(Fixed Size Chunking)、重叠分块(Overlap Chunking)、递归分块(Recursive Chunking)、文档特定分块(Document Specific Chunking)、语义分块(Semantic Chunking)、混合分块(Mix Chunking)。下面我将对这些策略逐一进行介绍。
- 我们可以通过分块可视化来看一下:(Chunk 切分可视化呈现链接: https://chunkviz.up.railway.app/)
- 固定大小分块(Fixed Size Chunking)
- 最基本的方法是将文档按固定大小进行分块,通常作为分块策略的基准线使用。
- 适用场景:适用于格式和大小相似的同质数据集,如新闻文章或博客文章。
- 问题:可能在句子或段落中断内容,导致无意义的文本块,缺乏灵活性,无法适应文本的自然结构。
- 重叠分块(Overlap Chunking)
- 通过滑动窗口技术切分文本块,使新文本块与前一个块的内容部分重叠,从而保留块边界处的重要上下文信息,增强系统的语义相关性。
- 适用场景:需要深入理解语义并保持上下文完整性的文档,如法律文档、技术手册或科研论文。
- 问题: 增加冗余信息的存储,处理效率降低。
- 递归分块(Recursive Chunking)
- 通过预定义的文本分隔符(如换行符\n\n、\n ,句号、逗号、感叹号、空格等)迭代地将文本分解为更小的块,以实现段大小的均匀性和语义完整性。此过程中,文本首先按较大的逻辑单元分割(如段落 \n\n),然后逐步递归到较小单元(如句子 \n 和单词),确保在分块大小限制内保留最强的语义片段。
- 适用场景: 这种方法适用于需要逐层分析的文本文档或需要分解成长片段、长段落的长文档,如研究报告、法律文档等。
- 问题: 不过仍有可能在块边界处模糊语义,容易将完整的语义单元切分开。
- 文档特定分块(Document Specific Chunking)
- 根据文档的格式(如 Markdown、Latex、或编程语言如 Python 等)进行定制化分割的技术。
- 适用场景: 这种方法可以根据特定的文档结构,进行准确的语义内容切分,在编程语言、Markdown、Latex 等结构文档中表现出色。
- 问题: 但文档特定分块的方式格式依赖性强,不同格式之间的分块策略不通用,并且无法处理格式不规范及混合多种格式的情况。
- 语义分块(Semantic Chunking)
- 基于文本的自然语言边界(如句子、段落或主题中断)进行分段的技术,需要使用 NLP 技术根据语义分词分句,旨在确保每个分块都包含语义连贯的信息单元。
- 常用的分块策略有 spaCy 和 NLTK 的 NLP 库,spaCy 适用于需要高效、精准语义切分的大规模文本处理,NLTK 更适合教学、研究和需要灵活自定义的语义切分任务。
- 适用场景:提高检索结果的相关性和准确性;复杂文档和上下文敏感的精细化分析。
- 问题:需要额外的计算资源,处理效率较低。
- 混合分块(Mix Chunking)
- 综合利用不同分块技术的优势,提高分块的精准性和效率。
- 根据实际业务场景,设计多种分块策略的混合,能够灵活适应各种需求,提供更强大的分块方案。
-
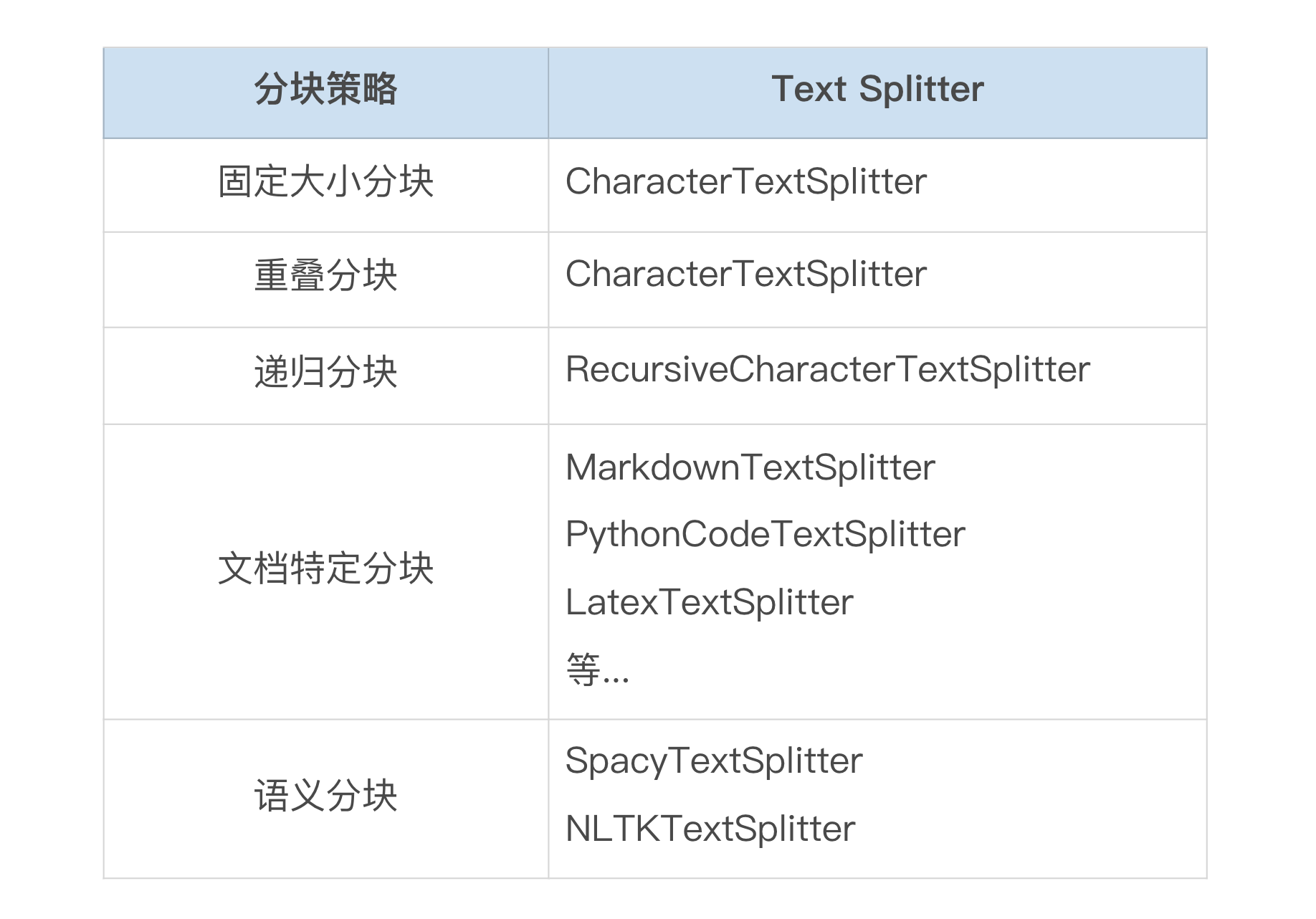
上述分块策略在 langchain_text_splitters 库中对应的具体方法类如下:
-
-
SpacyTextSplitter 和 NLTKTextSplitter 需要额外安装 Python 依赖库,其中 SpacyTextSplitter 还需要按照文档的语言对应安装额外的语言模型。
1
2
3
4conda activate rag # 激活虚拟环境
pip install spacy nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
python -m spacy download zh_core_web_sm # 如果需要进行中文分块,安装spacy中文语言模型
python -m spacy download en_core_web_sm # 如果需要进行英文分块,安装spacy英文语言模型- 导入 langchain.text_splitter 中各种文档分块类代码:
1
2
3
4
5
6
7
8
9from langchain.text_splitter import (
CharacterTextSplitter,
RecursiveCharacterTextSplitter,
MarkdownTextSplitter,
PythonCodeTextSplitter,
LatexTextSplitter,
SpacyTextSplitter,
NLTKTextSplitter
) # 从 langchain.text_splitter 模块中导入各种文档分块类-
CharacterTextSplitter、RecursiveCharacterTextSplitter、MarkdownTextSplitter、PythonCodeTextSplitter、LatexTextSplitter、NLTKTextSplitter 替换原有 text_splitter 参数的赋值类即可。
-
需要额外处理的是 SpacyTextSplitter,需要参数 pipeline 指定具体的语言模型才可以运行。
1
2# 配置SpacyTextSplitter分割文本块库
text_splitter = SpacyTextSplitter(chunk_size=512, chunk_overlap=128, pipeline="zh_core_web_sm") -
-