RAG索引(一):文档解析技术
RAG索引流程中面临的文档解析任务
1. 文档解析现状
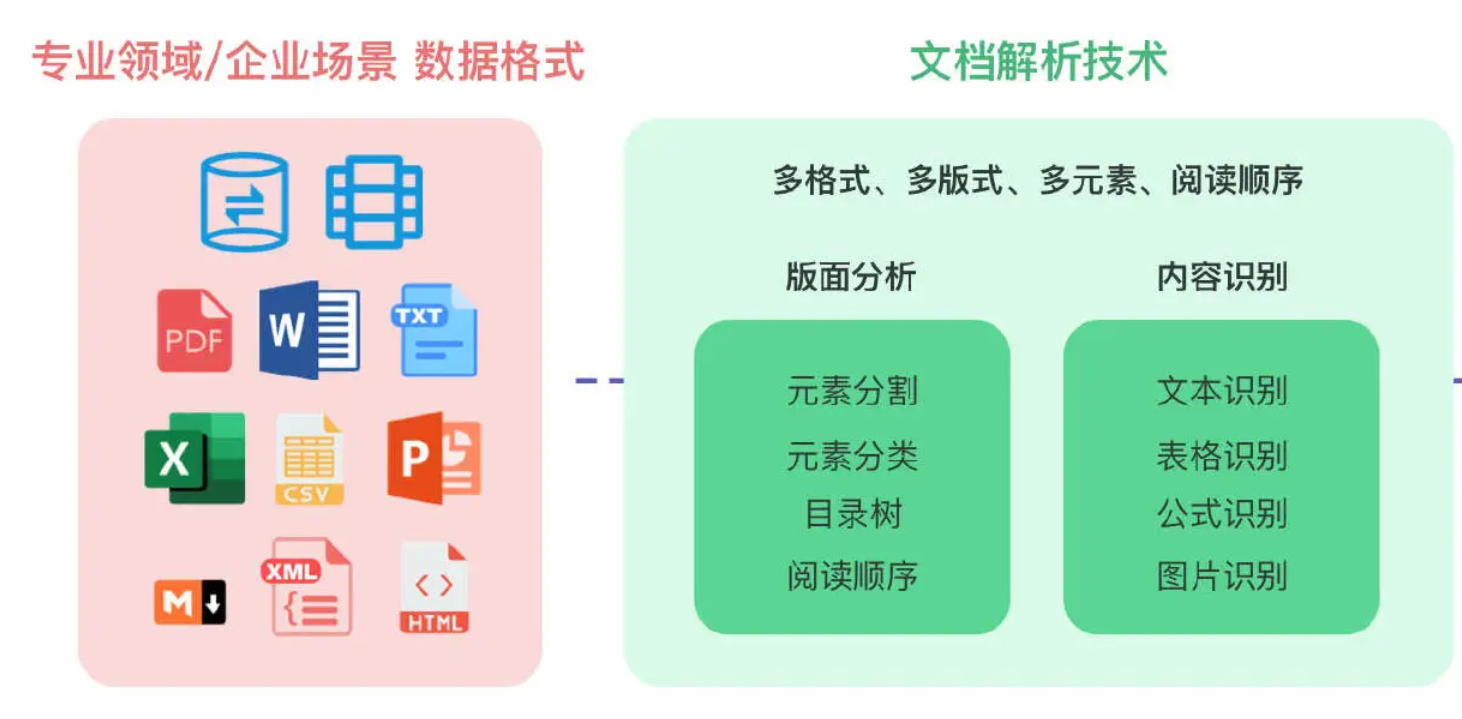
- 文档解析技术的本质在于将格式各异、版式多样、元素多种的文档数据,包括段落、表格、标题、公式、多列、图片等文档区块,转化为阅读顺序正确的字符串信息。
- 高质量的文档解析能够从各种复杂格式的非结构化数据中提取出高精准度的信息,对 RAG 系统最终的效果起决定性的作用。
- RAG应用场景中涉及的数据类型通常有:PDF、TXT、Word、PPT、Excel、CSV、Markdown、XML、HTML以及关系型和非关系型数据库等,这里面最常见也是最难的就是PDF的解析。
- PDF 文档往往篇幅巨大、页数众多,且企业及专业领域 PDF 文件数据量庞大,因此文档解析技术还需具备极高的处理性能,以确保知识库的高效构建和实时更新。
2. 文档解析工具选择(这里主要讨论开源工具)
-
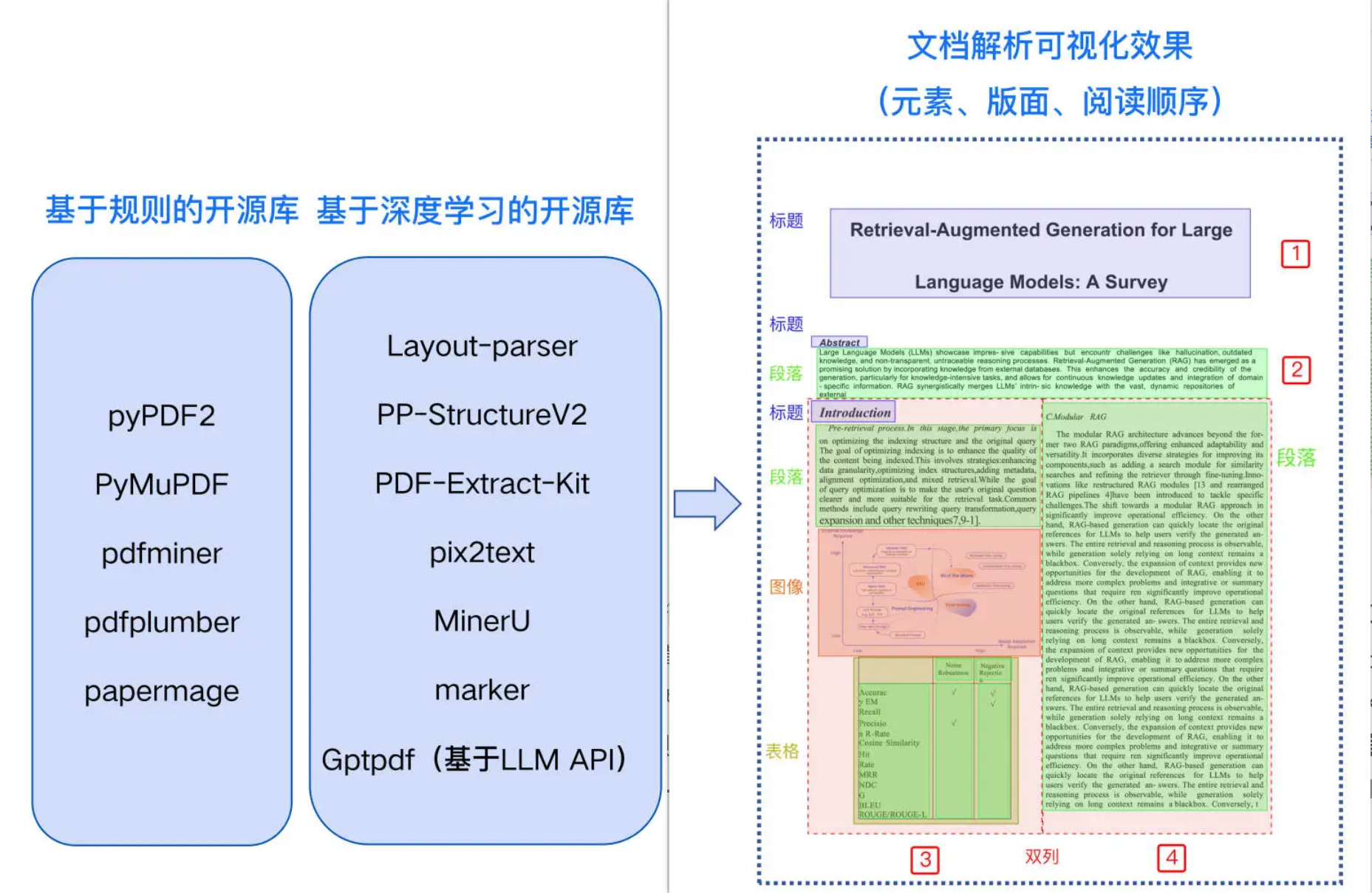
我们可以把所有工具分为两大类
- 一个是基于规则的开源库
- 一个是基于深度学习的开源库
-
这里我们首先介绍基于规则的解析工具
- 因为我们选择的框架langchain提供在实际应用场景中常见文档格式基于规则的解析方案,涵盖 PDF、TXT、Word、PPT、Excel、CSV、Markdown、XML 和 HTML 格式。
- 所以初步使用langchain框架LangChain Document Loaders 文档加载器进行操作,也就是langchain_community.document_loaders模块。
- 以下是langchain Document Loader 所需的文档解析依赖库
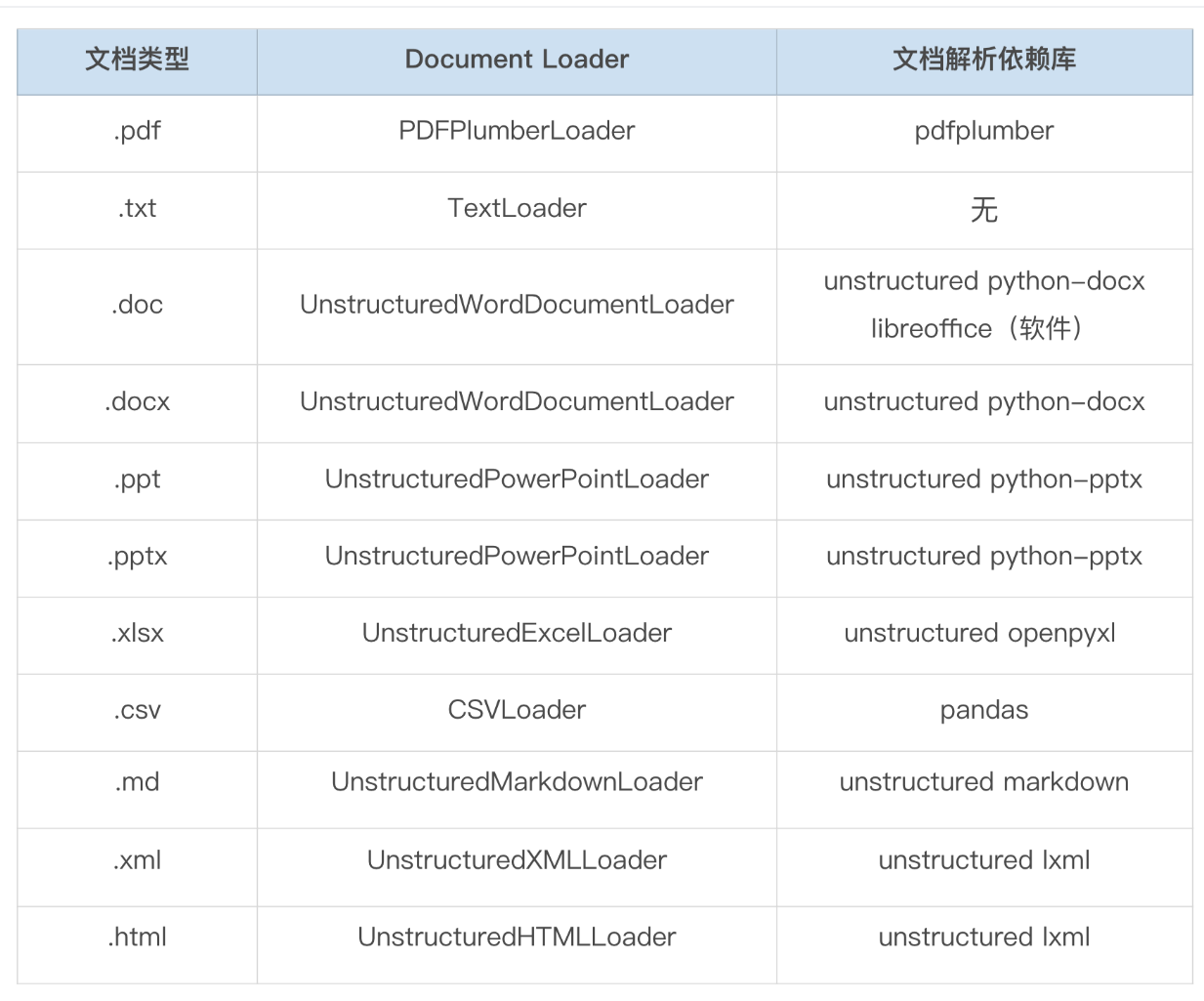
- 例如,当我们项目中使用 from langchain_community.document_loaders import PDFPlumberLoader 时,需要先通过命令行 pip install pdfplumber 安装 pdfplumber 库。某些特殊情况下,还需要额外的依赖库,比如使用 UnstructuredMarkdownLoader 时,需要安装 unstructured 库来提供底层文档解析,还需要 markdown 库来支持 Markdown 文档格式更多能力。此外,对于像 .doc 这种早期的文档类型,还需要安装 libreoffice 软件库才能进行解析。
- 针对PDF文档,目前主流是转为MarkDown文件格式。PDF 文件分为电子版和扫描版,**PDF 电子版可以通过规则解析,提取出文本、表格等文档元素。**目前,有许多开源库可以支持,例如 pyPDF2、PyMuPDF、pdfminer、pdfplumber 和 papermage 等。这些库在 langchain_community.document_loaders 中基本都有对应的加载器。
- 在基于规则的开源库中,pdfplumber 对中文支持较好,且在表格解析方面表现优秀,但对双栏文本的解析能力较差;pdfminer 和 PyMuPDF 对中文支持良好,但表格解析效果较弱;pyPDF2 对英文支持较好,但中文支持较差;papermage 集成了 pdfminer 和其他工具,特别适合处理论文场景。开发者可以根据实际业务场景的测试结果选择合适的工具,pdfplumber 或 pdfminer 都是当前不错的选择。
-
再来看基于深度学习的开源解析工具
- 基于深度学习的工具基本都是因PDF而生,无论扫描版还是电子版均需进行版面分析和阅读顺序的还原,将内容解析为一个包含所有文档元素并且具有正确阅读顺序的 MarkDown 文件。单纯依赖规则解析是无法实现这一目标的,目前支持这些功能的多为基于深度学习的开源库,如 Layout-parser、PP-StructureV2、PDF-Extract-Kit、pix2text、MinerU、marker 等。
- 由于深度学习模型的部署复杂性以及对显卡配置的要求,langchain目前基本集成的都是基于规则的解析工具,基于深度学习的工具需要进行独立部署。
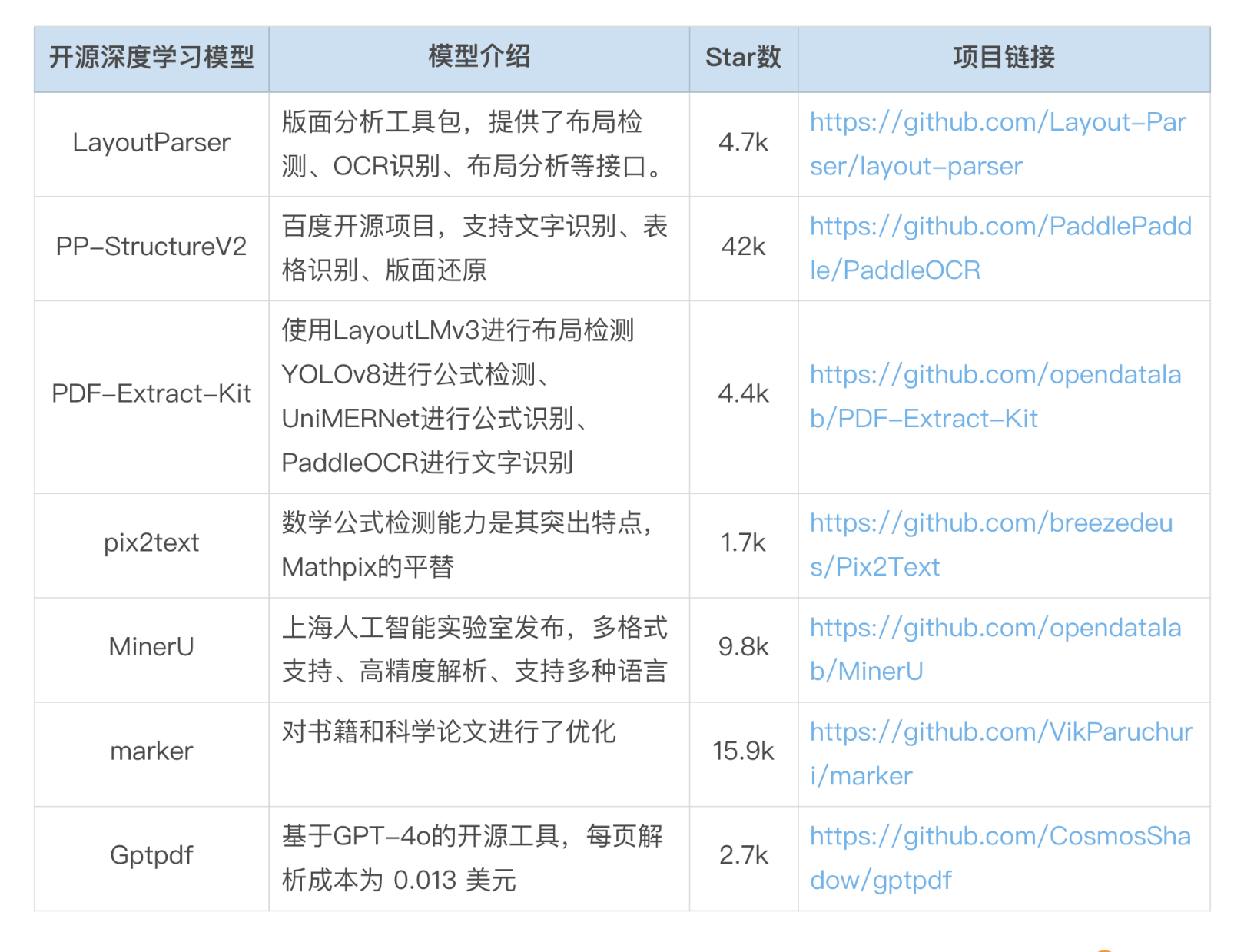
- 除了以上提到的还有比如:RapidLayout 专注于版面分析的,以及众多专注OCR(光学字符识别)识别的ZeroX,GOT-OCR2.0, OCRmyPDF,olmOCR等。
-
目前除了这些工具,采用 端到端的多模态大模型直接解析 包括文字模态以及图片中非文字内容的解析,如常见的折线图、柱状图等,也许是文档解析的终极形式,但模型在效率和成本方面仍存在挑战,但其未来潜力巨大,值得期待。