rag-lesson-1
从 0 到 1 快速搭建 RAG 应用
-
技术框架与选型
-
RAG 技术框架:LangChain
- LangChain 是专为开发基于大型语言模型(LLM)应用而设计的全面框架,其核心目标是简化开发者的构建流程,使其能够高效创建 LLM 驱动的应用。
-
索引流程 - 文档解析模块:pypdf
- pypdf 是一个开源的 Python 库,专门用于处理 PDF 文档。pypdf 支持 PDF 文档的创建、读取、编辑和转换操作,能够有效提取和处理文本、图像及页面内容。
-
索引流程 - 文档分块模块:RecursiveCharacterTextSplitter
- 采用 LangChain 默认的文本分割器 -RecursiveCharacterTextSplitter。该分割器通过层次化的分隔符(从双换行符到单字符)拆分文本,旨在保持文本的结构和连贯性,优先考虑自然边界如段落和句子。
-
索引 / 检索流程 - 向量化模型:BAAI/bge-m3
- bge-m3 是由北京人工智能研究院(BAAI,智源)开发的开源向量模型。能够提供高精度和高效的中文向量检索。该模型的向量维度为 1024,最大输入长度同样为 8k。
-
索引 / 检索流程 - 向量库:Faiss
- Faiss 全称 Facebook AI Similarity Search,由 Facebook AI Research 团队开源的向量库,因其稳定性和高效性在向量检索领域广受欢迎。
-
生成流程 - 大语言模型:SiliconCloud(硅基流动)的 Qwen/Qwen2.5-7B-Instruct
- Qwen/Qwen2.5-7B-Instruct 是阿里开源的一款 chat 大语言模型,支持对话、文案创作、逻辑推理、以及多语言处理,在模型性能和工程应用中表现出色。
-
上述选型在 RAG 流程图中的应用如下所示:
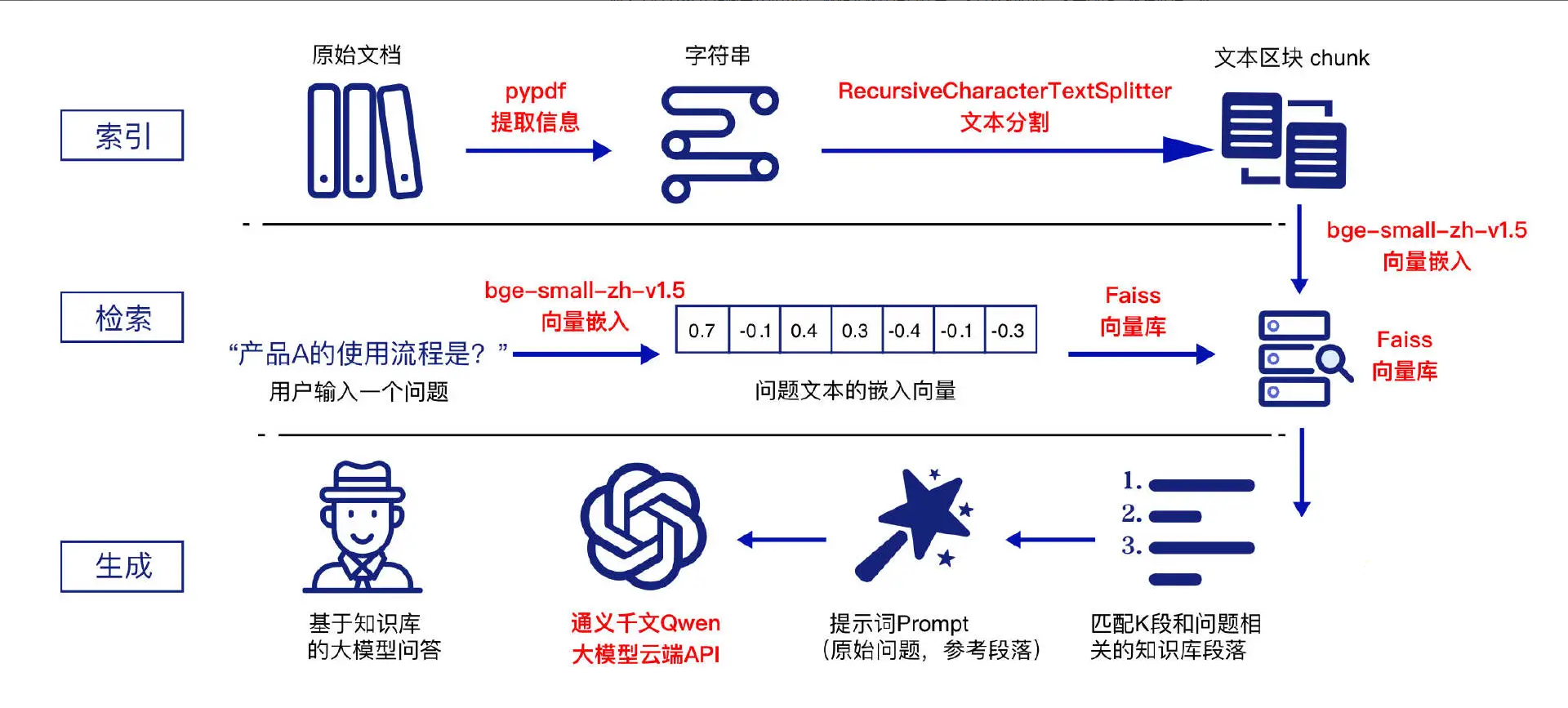
- LangChain:提供用于构建 LLM RAG 的应用程序框架。
- 索引流程:使用 pypdf 对文档进行解析并提取信息;随后,采用 RecursiveCharacterTextSplitter 对文档内容进行分块(chunks);最后,利用 bge-3m 将分块内容进行向量化处理,并将生成的向量存储在 Faiss 向量库中。
- 检索流程:使用 bge-3m 对用户的查询(Query)进行向量化处理;然后,通过 Faiss 向量库对查询向量和文本块向量进行相似度匹配,从而检索出与用户查询最相似的前 top-k 个文本块(chunk)。
- 生成流程:通过设定提示模板(Prompt),将用户的查询与检索到的参考文本块组合输入到 Qwen 大模型中,生成最终的 RAG 回答。
-
-
开发环境与技术库
-
准备windows系统, pycharm开发工具, Miniconda(python环境管理工具)
-
创建并激活虚拟环境
1
2conda create -n rag python=3.11 # 创建名为rag的虚拟环境
conda activate rag # 激活虚拟环境 -
安装技术依赖库
1
2
3pip install langchain langchain_community pypdf sentence-transformers faiss-cpu
# 无法安装,可以使用国内镜像源,命令如下:
pip install langchain langchain_community pypdf sentence-transformers faiss-cpu -i https://pypi.tuna.tsinghua.edu.cn/simple -
课程中用到的代码和pdf文件分享在github上:
-